Recall that violations of model assumptions are more likely at remote points, and these violations may be hard to detect from inspection of the ordinary residuals because their residuals will usually be smaller. Points that are outlying in the \(x\)-direction are known as leverage points. Influential points are not only remote in terms of the specific values for the regressors, but the observed response is not consistent with the values that would be predicted based on only the other data points. It is important to find these influential points and assess their impact on the model.
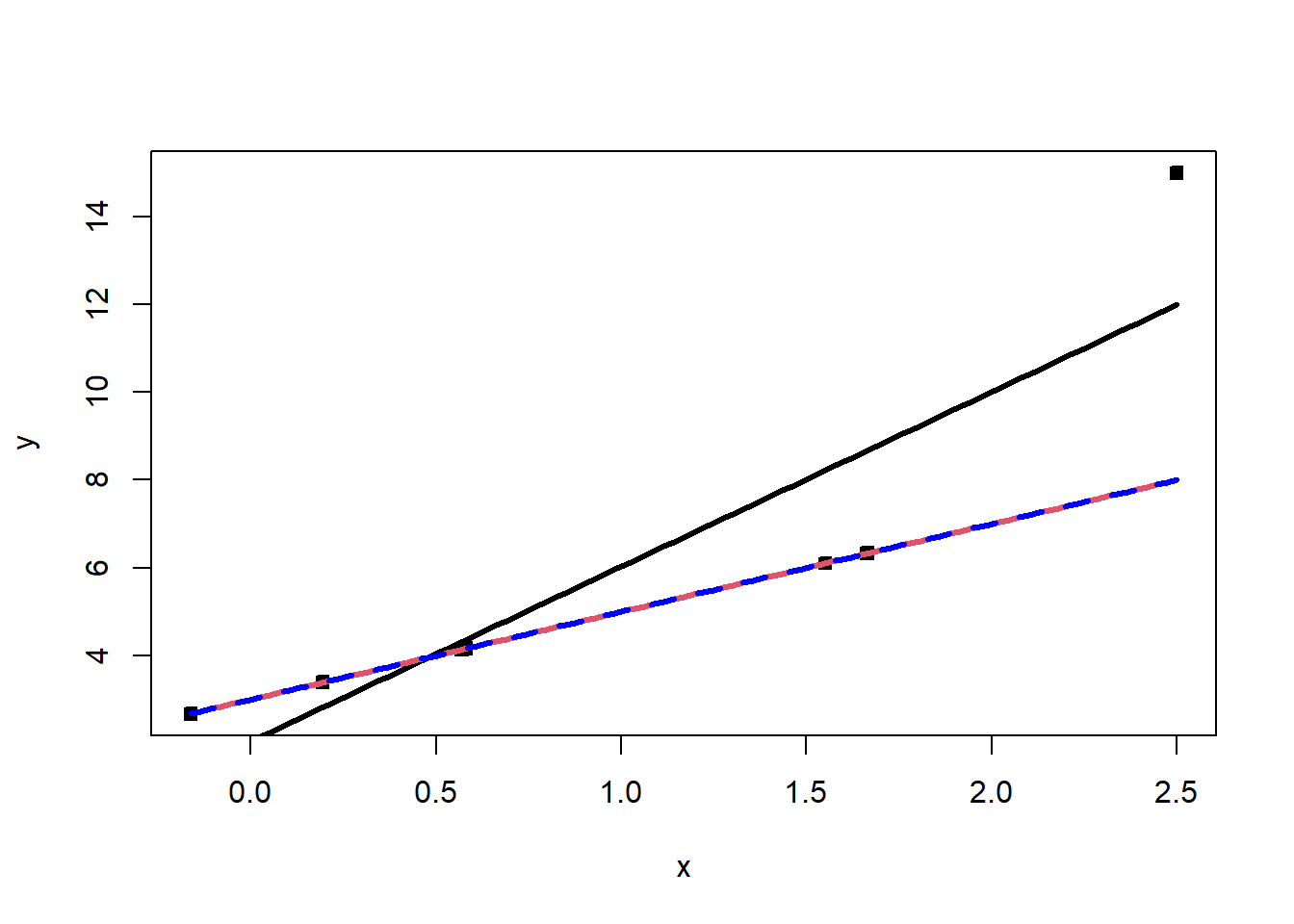
Below gives an example of an influential point. The seventh point in the data set is outlying in the \(x\)-direction, and it’s response value is not consistent with the regression line based on the other six observations:
Sometimes we find that a regression coefficient may have a sign that does not make engineering or scientific sense, a regressor known to be important may be statistically insignificant, or a model that fits the data well and that is logical from an application – environment perspective may produce poor predictions. These situations may be the result of one or, perhaps, a few influential observations.
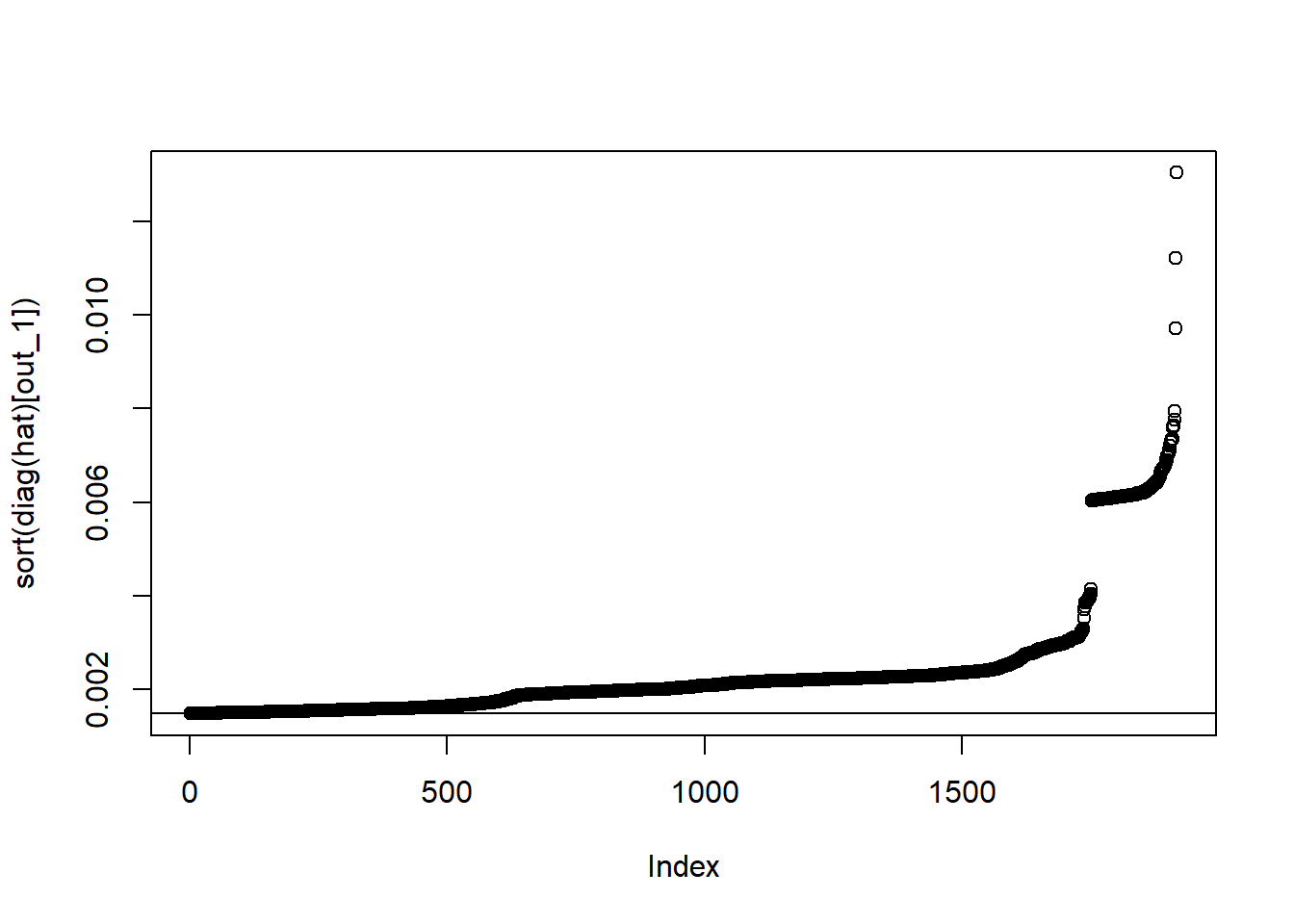
Recall the hat matrix \(H=X(X^\top X)^{-1}X^\top\), as well as that it holds that \({\textrm{Var}}\left[\hat\epsilon\right]=\sigma^2(I-H)\) and \({\textrm{Var}}\left[\hat Y\right]=\sigma^2 H\). Note that \(h_{ij}\) can be interpreted as the amount of leverage exerted by the \(ith\) observation \(y_i\) on the \(jth\) fitted value \(\hat y_j\). We usually focus attention on the diagonal elements \(h_{ii}\) of the hat matrix \(H\), which may be written as \[h_{ii}=x_i^\top (X^\top X)^{-1} x_i,\] where \(X_i^\top\) is the \(i\)th row of \(X\). The hat matrix diagonal is a standardized measure of the distance of the \(i\)th observation from the center (or centroid) of the \(x\)-space. Therefore, large values of \(h_{ii}\) implies that \(x_i\) is potentially influential. Furthermore, note that \(rank(H)=p\) since the trace of an idempotent matrix equals its rank, which means that \(\bar h= p/n\). It follows that values well above \(p/n\), say \(h_{ii}>2p/n\), can be called leverage points.
Cook’s Distance is one way to incorporate both the \(X\) and \(Y\) values into an outlyingness measure:
\[
D_i\left(X^{\top} X, p, MSE\right) \equiv D_i=\frac{\left(\hat{\beta}_{(i)}-\hat{\beta}\right)^{\top} X^{\top} X\left(\hat{\beta}_{(i)}-\hat{\beta}\right)}{p MSE}, \ i\in [n],
\] where \(\hat{\beta}_{(i)}\) is the OLS estimator with the \(i\)th point removed.Large values of Cook’s distance signal a leverage point.
What do we mean by a large value? We can compare \(D_i\) to the 50th percentile of the \(F_{p,n-p}\) distribution. This gives the interpretation that deleting the \(i\)th point moves the estimate to the boundary of a 50% confidence interval. \(F_{p,n-p}\approx 1\), and so usually take \(D_i\geq 1\) to be large.
Observe that \[
D_i=\frac{r_i^2}{p} \frac{\operatorname{Var}\left(\hat{Y}_i\right)}{\operatorname{Var}\left(\hat\epsilon_i\right)}=\frac{r_i^2}{p} \frac{h_{i i}}{1-h_{i i}}, \quad i=1,2, \ldots, n,\] where it is important to recall that \(r_i\) is the studentized residual. Now, the quantity \(\frac{h_{i i}}{1-h_{i i}}\) can be shown to be the distance from the vector \(x_i\) to the centroid of the remaining data. Therefore, \(D_i\) is the product of outlyingness in both the \(X\) and \(Y\) directions. We may also write \(D_i\) as \[D_i=\frac{\left\lVert\hat{y}_{(i)}-\hat{y}\right\rVert^2}{p MSE},\] which allows for the interpretation: The Cook’s distance of the \(i\)th point is the normalized distance between the fitted value with and without point \(i\).
A more modern approach and nonparametric approach to outlier detection is through data depth. A data depth function gives meaning to centrality, order and outlyingness in spaces beyond \(\mathbb{R}\). A data depth function is a function which takes a sample and a point, and returns how central the point is, with respect to the sample. Depth functions can be written as \({\textrm{D}}\colon \mathbb{R}^{d}\times \text{Sample} \rightarrow \mathbb{R}^+\). There are different definitions of depth, so I will give a few.
Let \(S^{d-1}= \{x\in \mathbb{R}^{d}\colon \left\lVert x\right\rVert=1\}\) be the set of unit vectors in \(\mathbb{R}^{d}\), let \(\mathbb{X}_{n}=\{(Y_1,X_{1,1},\ldots,X_{1,p-1}),\ldots, (Y_n,X_{n,1},\ldots,X_{n,p-1})\}\), let \(\mathbb{X}_{n}^\top u\) be \(\mathbb{X}_{n}\) projected onto \(u\in S^{d-1}\) and let \(\widehat F_u\) be the empirical CDF with respect to \(\mathbb{X}_{n}^\top u\).
The halfspace depth \({\textrm{D}}_H\) of a point \(x\in \mathbb{R}^{d}\) with respect to a distribution \(F\) over \(\mathbb{R}^{d}\) is \[
{\textrm{D}}_H(x;F)=\inf_{u\in S^{d-1}} \widehat F_u(x^\top u)\wedge (1-F_u(x^\top u))=\inf_{u\in S^{d-1}}
F_u(x^\top u).
\]
Given a translation and scale equivariant location estimate \(\mu\) and a translation and scale invariant scale estimate \(\sigma\), the outlyingness at \(x\in\mathbb{R}^{d}\) is defined as \[O(x)=\sup _{u\in S^{d-1}} \frac{\left|x^\top u-\mu(\mathbb{X}_{n}^\top u)\right|}{\sigma(\mathbb{X}_{n}^\top u)}.\] Define projection depth as \[{\textrm{D}}_p(x)=(1+O(x))^{-1}.\]
In order to detect outliers, we look for observations that have low depth. See, continuing our toy example:
Example 7.1 Recall example Example 6.6. Check for leverage and influential points in the proposed models. Compute all three measures of leverage/influence/outlyingness introduced in this lesson. What do you find?
I will load in the data below:
We can now analyze the data:
####### Loading data ##############df_clean2=read.csv('C:/Users/12RAM/OneDrive - York University/Teaching/Courses/Math 3330 Regression/Lecture Codes/clean_data.csv',stringsAsFactors = T)####### Analyzing the data via EDA ##############names(df_clean2)
# Convert to factorsdf_clean2$District=as.factor(df_clean2$District)df_clean2$Extwall=as.factor(df_clean2$Extwall)df_clean2$Stories=as.factor(df_clean2$Stories)df_clean2$Fbath=as.factor(df_clean2$Fbath)df_clean2$Bdrms=as.factor(df_clean2$Bdrms)df_clean2$Units=as.factor(df_clean2$Units)# df_clean2=df_clean2[,c('Sale_price','Fin_sqft',# 'District','Sale_date','Year_Built','Lotsize')]# We are not going to remove the outliers that we found earlier , and see if these diagnostics detect it# remove those with 0 lot size# df3=df_clean2[df_clean2$Lotsize>0,]# df4=df3[df3$Lotsize<150000,]df5=df_clean2[df_clean2$District!=3,]df5$District=droplevels(df5$District)# Old modelmodel=lm(sqrt(Sale_price)~Fin_sqft+District+Sale_date+ Year_Built,data=df5)summary(model)
# First measureX=model.matrix(model)hat=X%*%solve(t(X)%*%X)%*%t(X)# diag(hat)p=ncol(X)n=nrow(X)out_1=which(diag(hat)>2*p/n)plot(sort(diag(hat)[out_1]))abline(h=2*p/n)
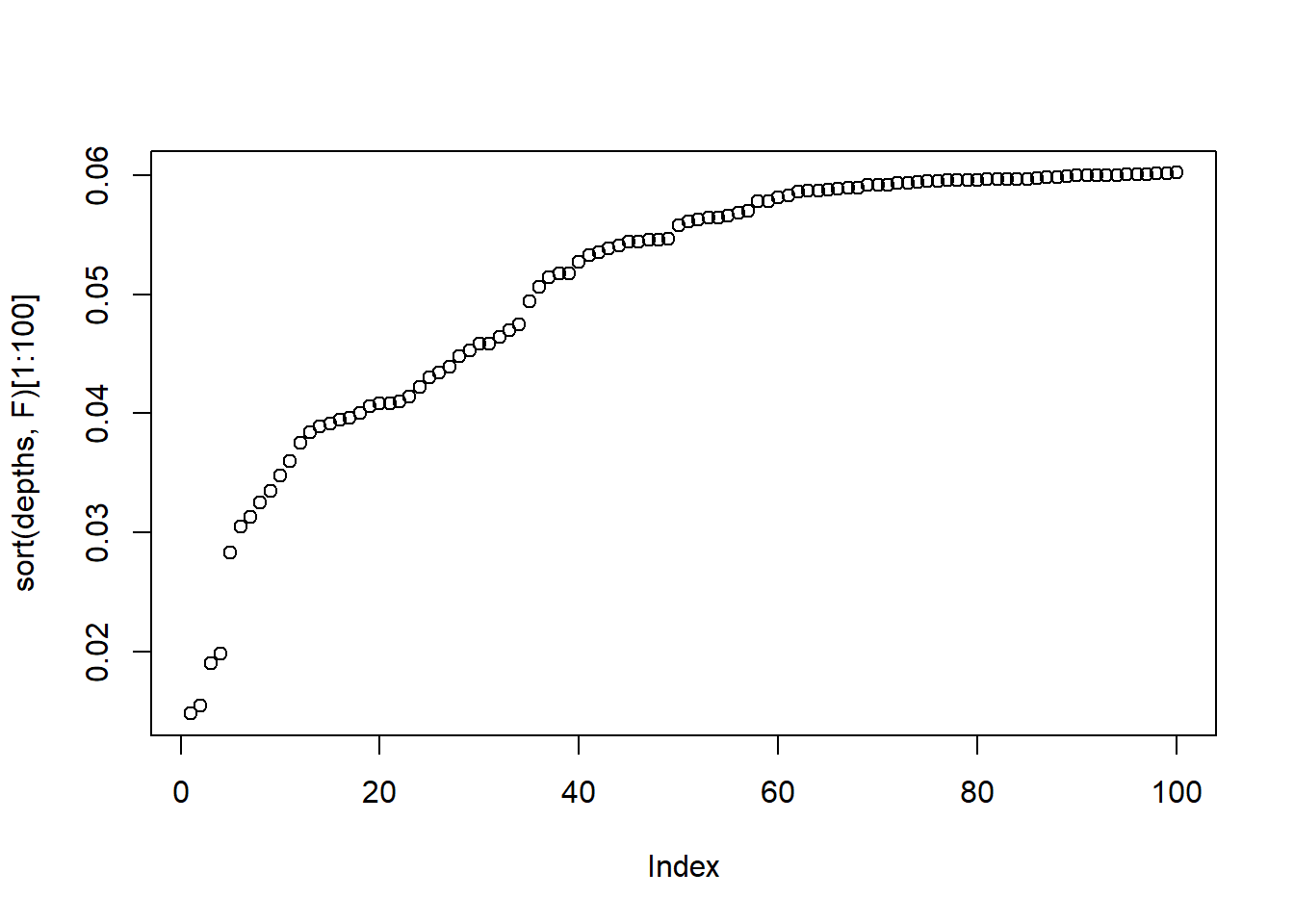
# I would still look at those after the elbow# There is a large break# Cooks distancesCDS=cooks.distance(model)plot(sort(CDS,T)[1:100])
which(CDS>1)
named integer(0)
max(CDS)
[1] 0.01361538
df[CDS>1,]
[1] y x
<0 rows> (or 0-length row.names)
# I would still look at those two values that are # far from the other distances# I would still look at those before the elbow# We may only look at numeric values for depth functions - so we can eithernumer=NULLfor(i innames(df5)){if(!is.factor(df5[1,i])){ numer=c(numer,i) }}numer
# what happens when we remove some variables?model2=lm(sqrt(Sale_price)~Fin_sqft+District+Sale_date+Year_Built,data=df5[-order(CDS,decreasing = T)[1:100],])summary(model)
# Notice that some of the coefficients moved several standard errors!! This is a huge change - recall that outside 2 SE is outside the confidence interval. sort(abs(model2$coefficients-model$coefficients)/s$coefficients[,2],T)
How should we treat influential observations? The easiest course of action is removal. If there are many influential observations, then you might want to try robust model fitting methods, which automatically account for outliers and influential observations.
7.4 Homework questions
Complete the Chapter 6 textbook questions.
Exercise 7.1 What are the three methods we have learned for detecting influential/leverage points?
Exercise 7.2 Compute the hat values, Cook’s distances and the depth values for the body weight example. Are there any influential/leverage points/outliers?
Exercise 7.3 Compute the hat values, Cook’s distances and the depth values for the cars example. Are there any outliers/influential/leverage points?
Exercise 7.4 Fit a model without location to the real estate data of your choosing. Compute the hat values, Cook’s distances and the depth values for the cars example. Are there any influential/leverage points/outliers? Print out the influential/leverage points/outliers. Why do you think they are outlying? Should we remove them?