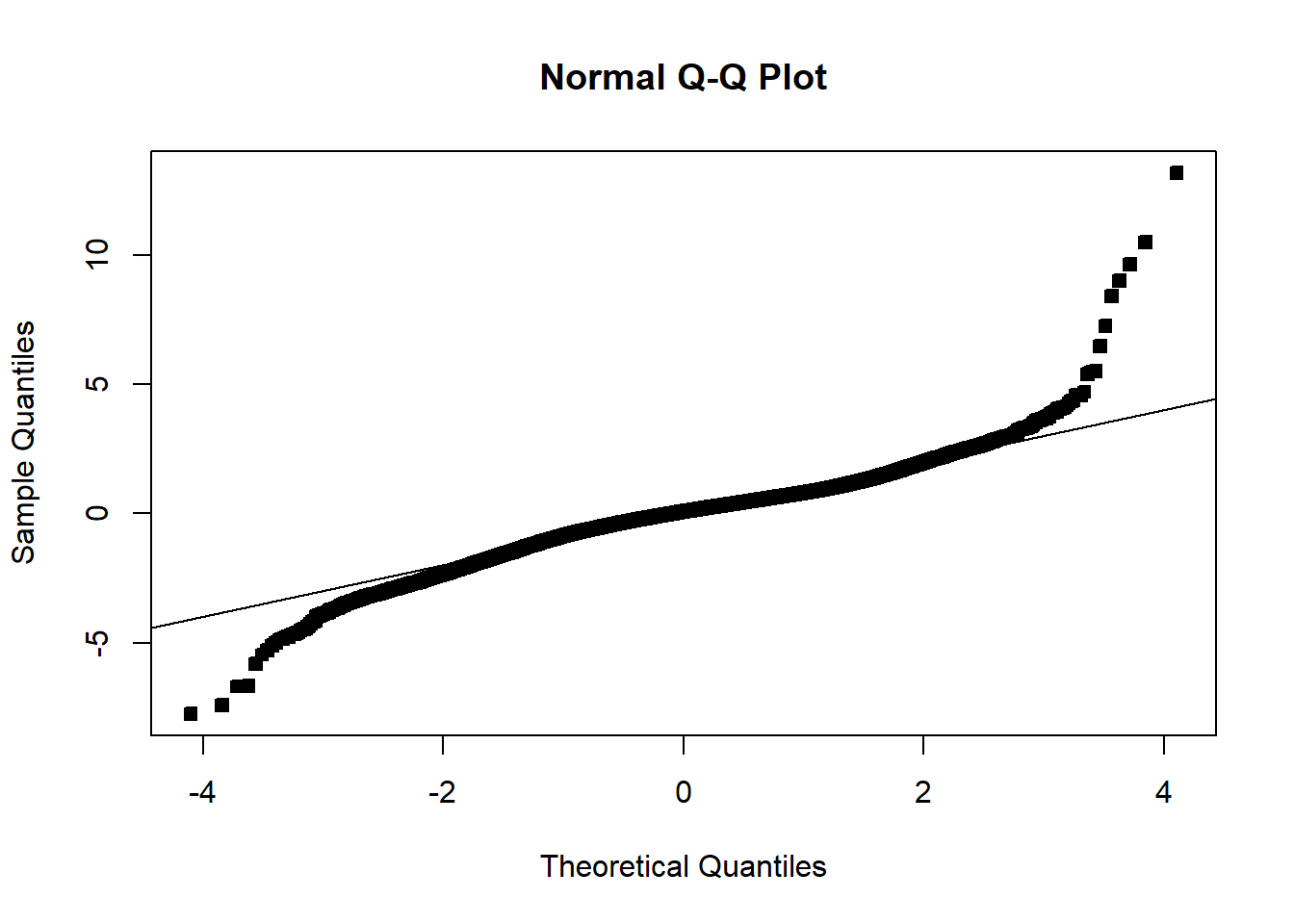
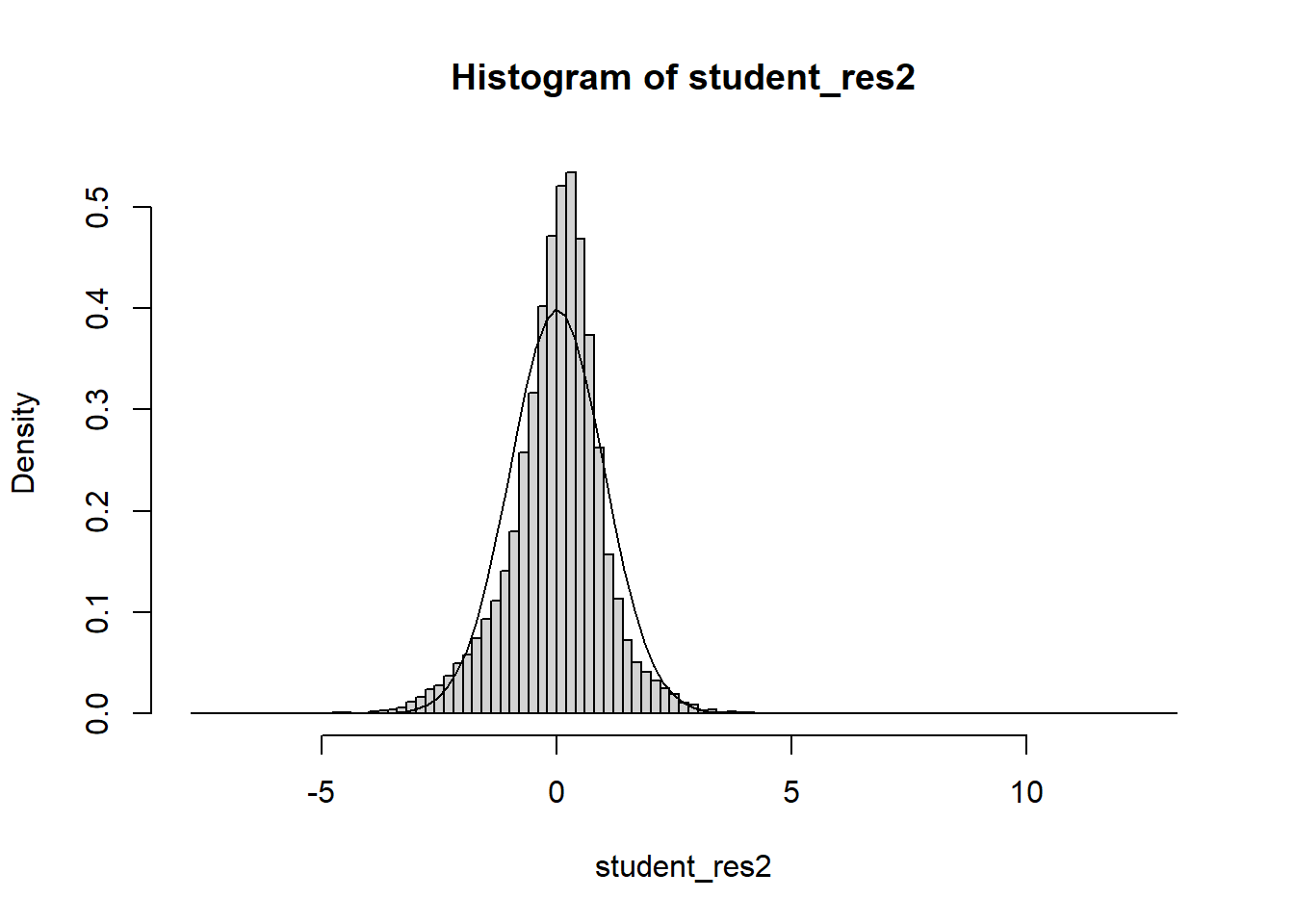
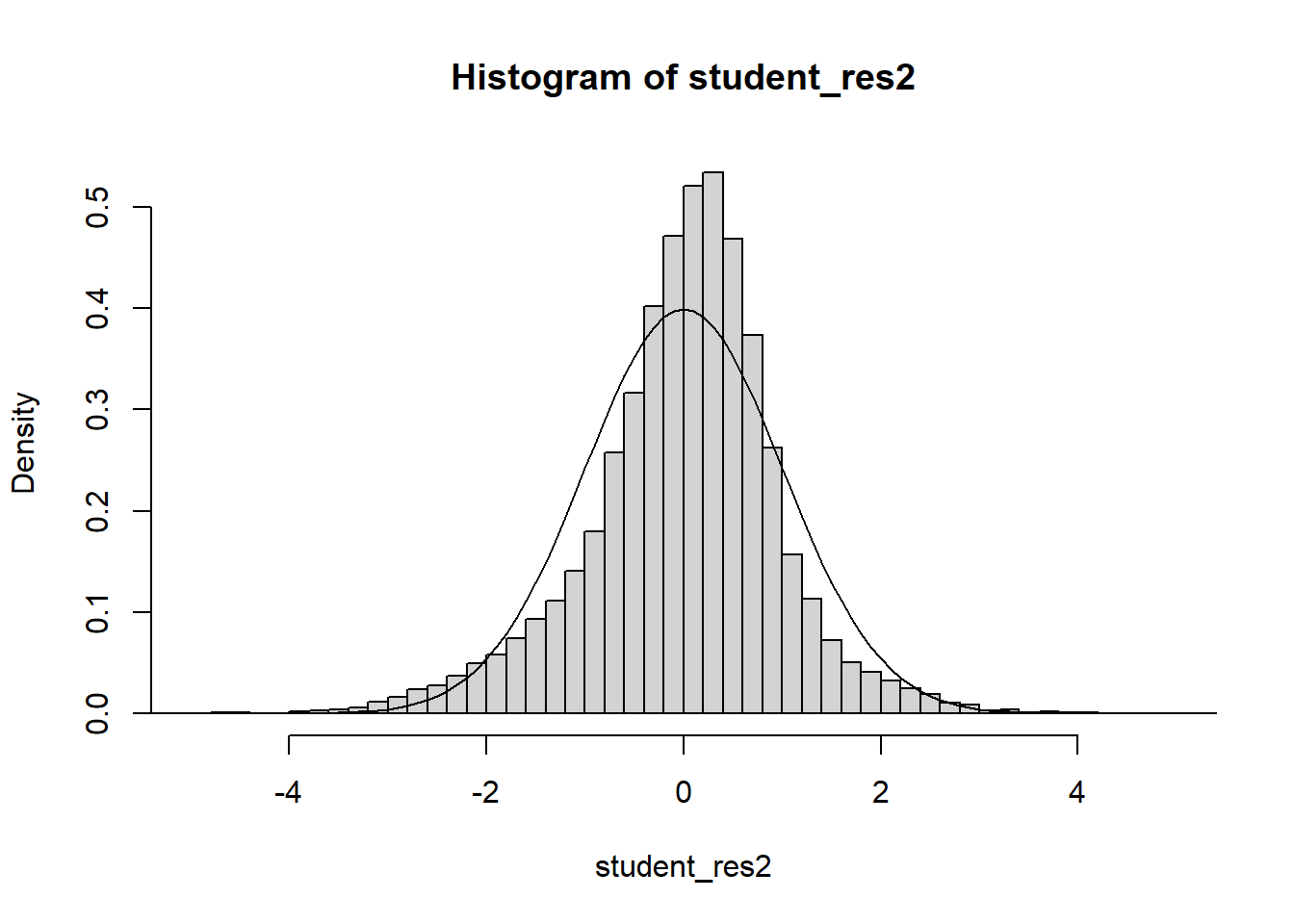
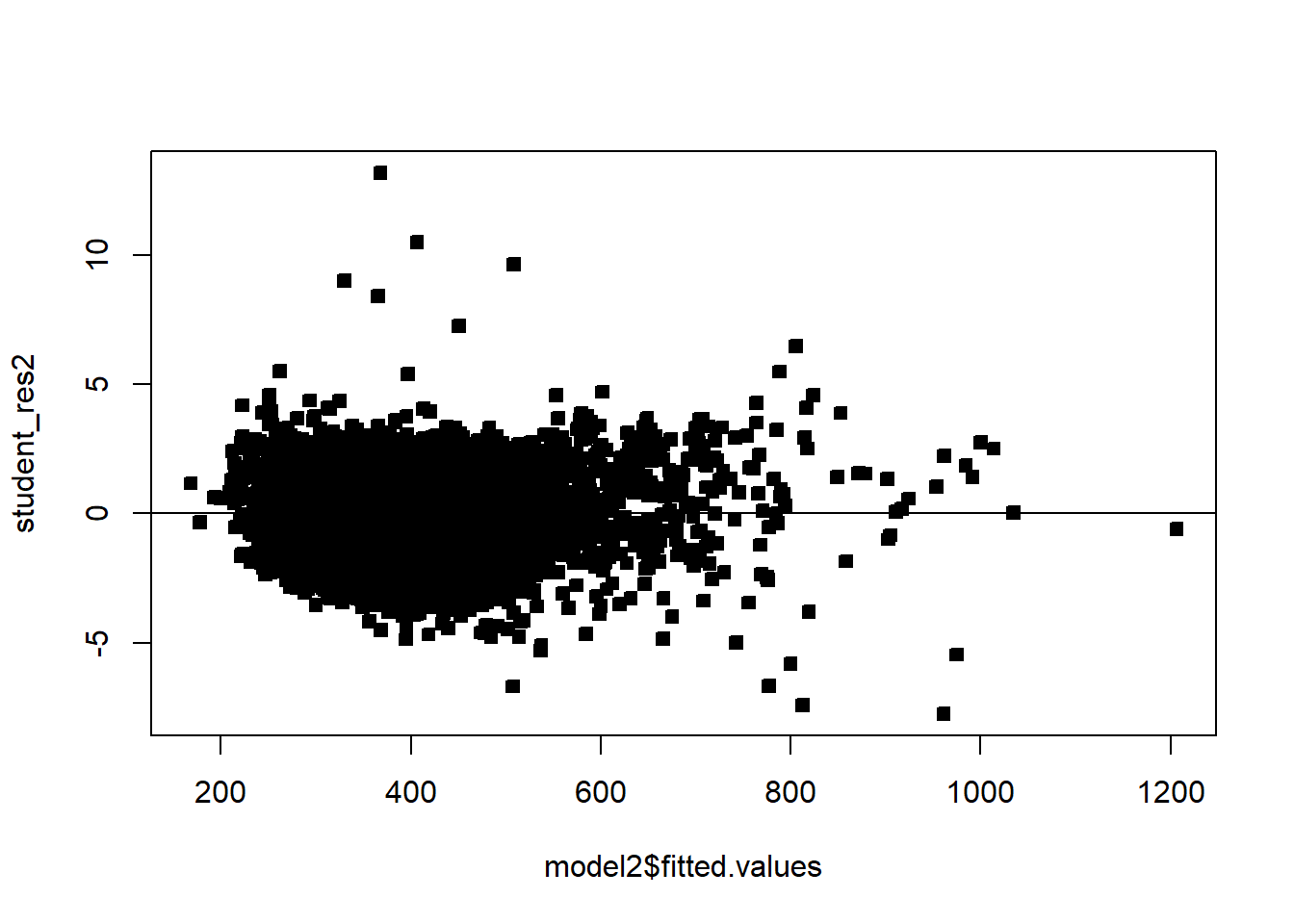
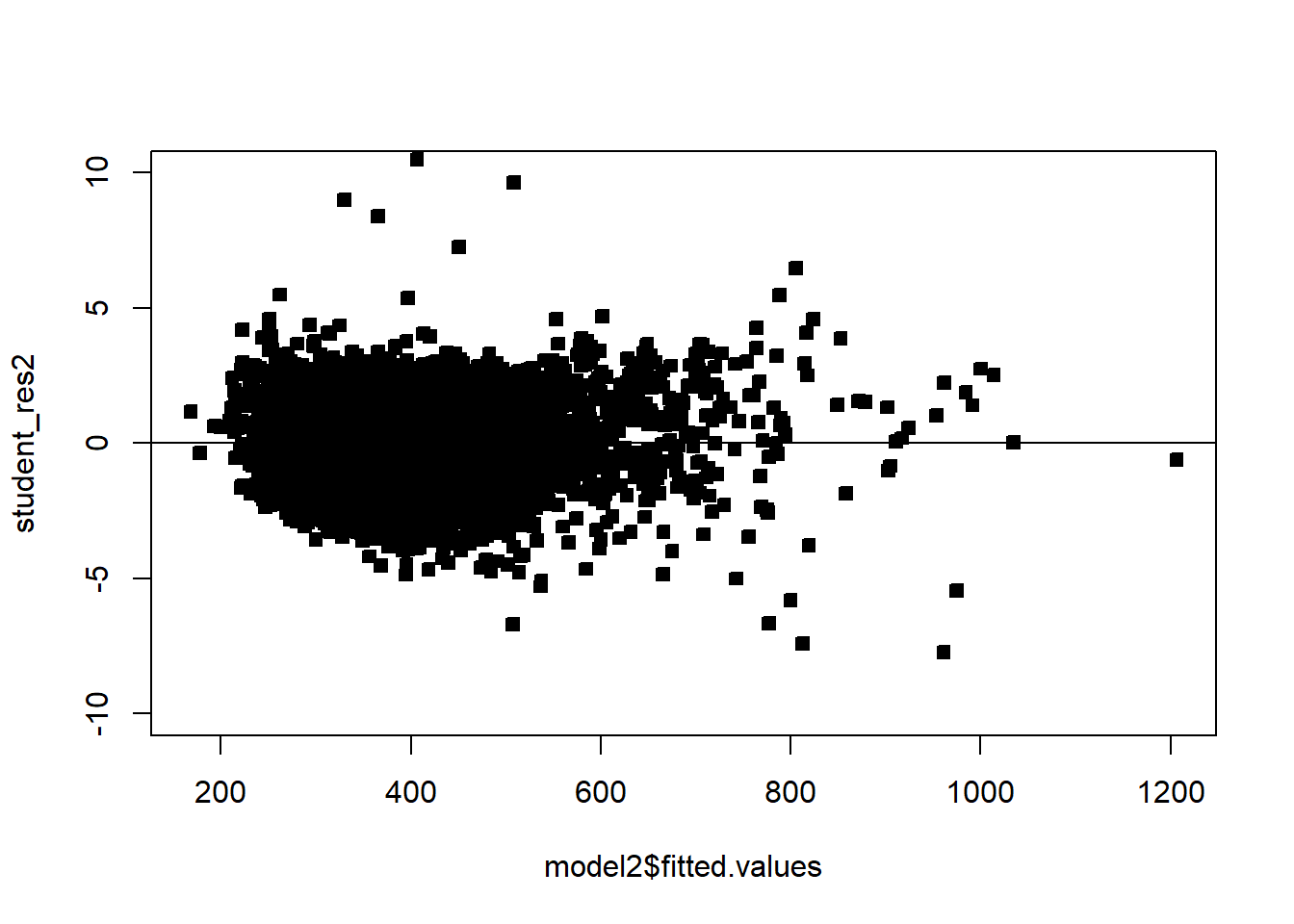
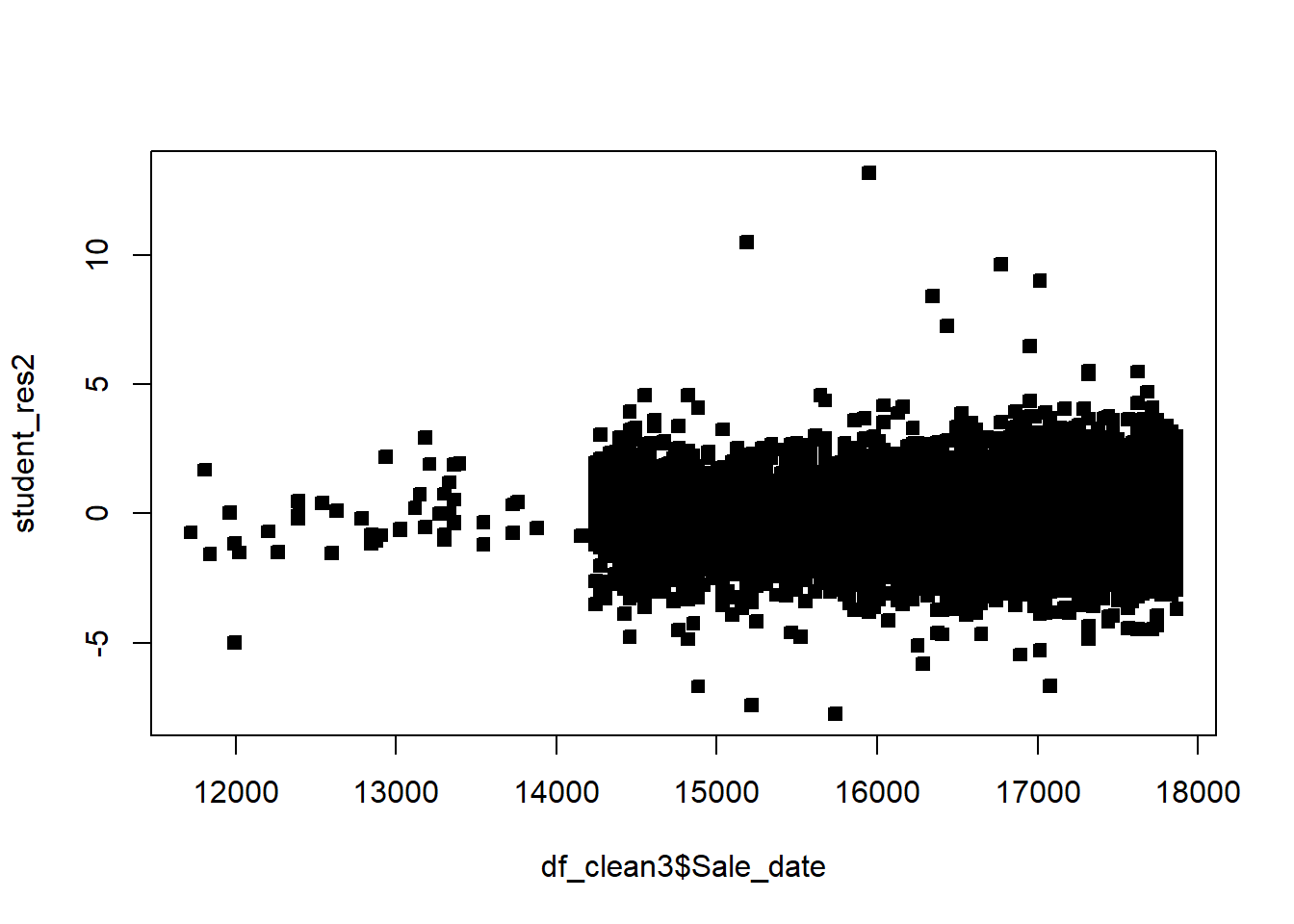
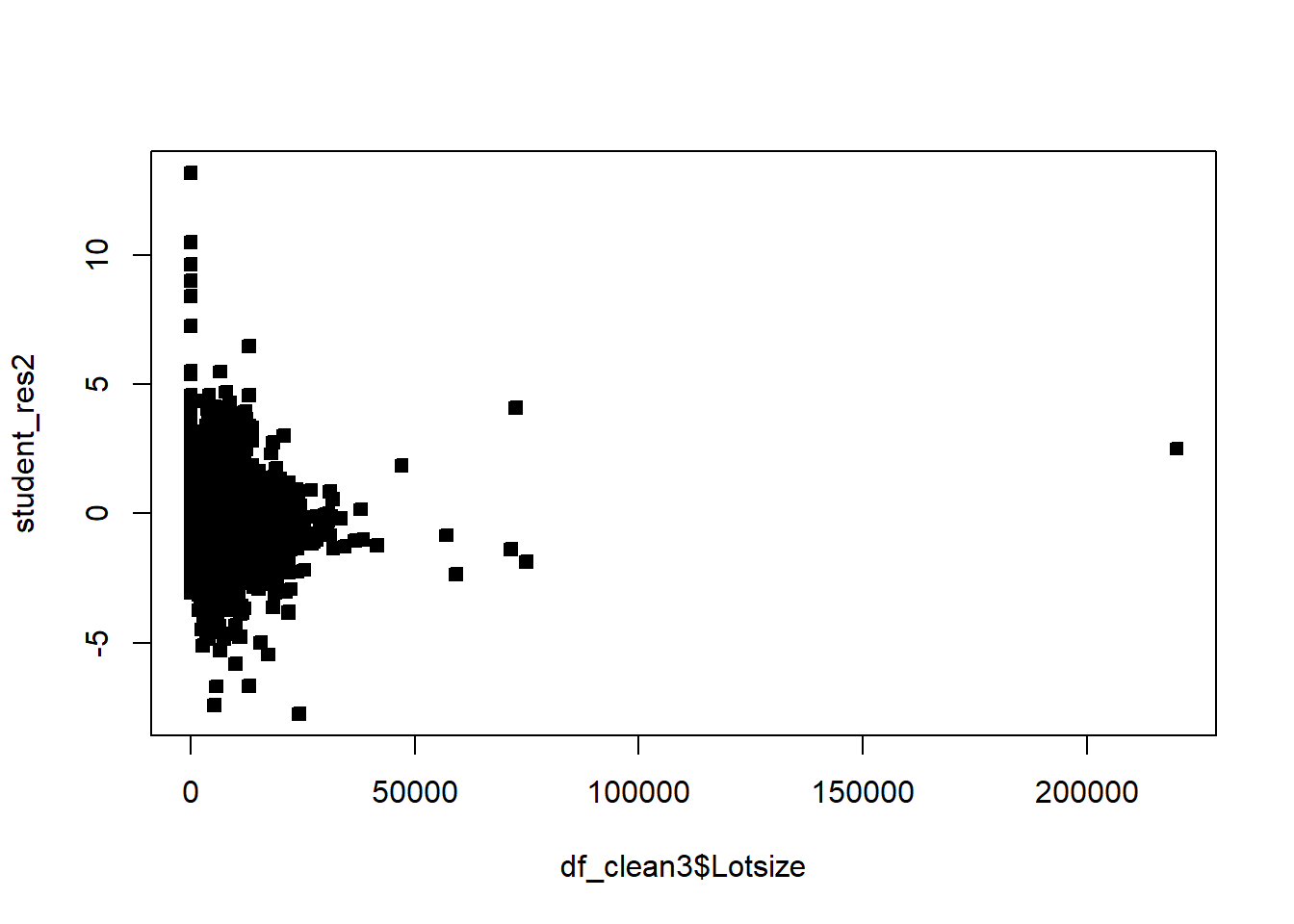
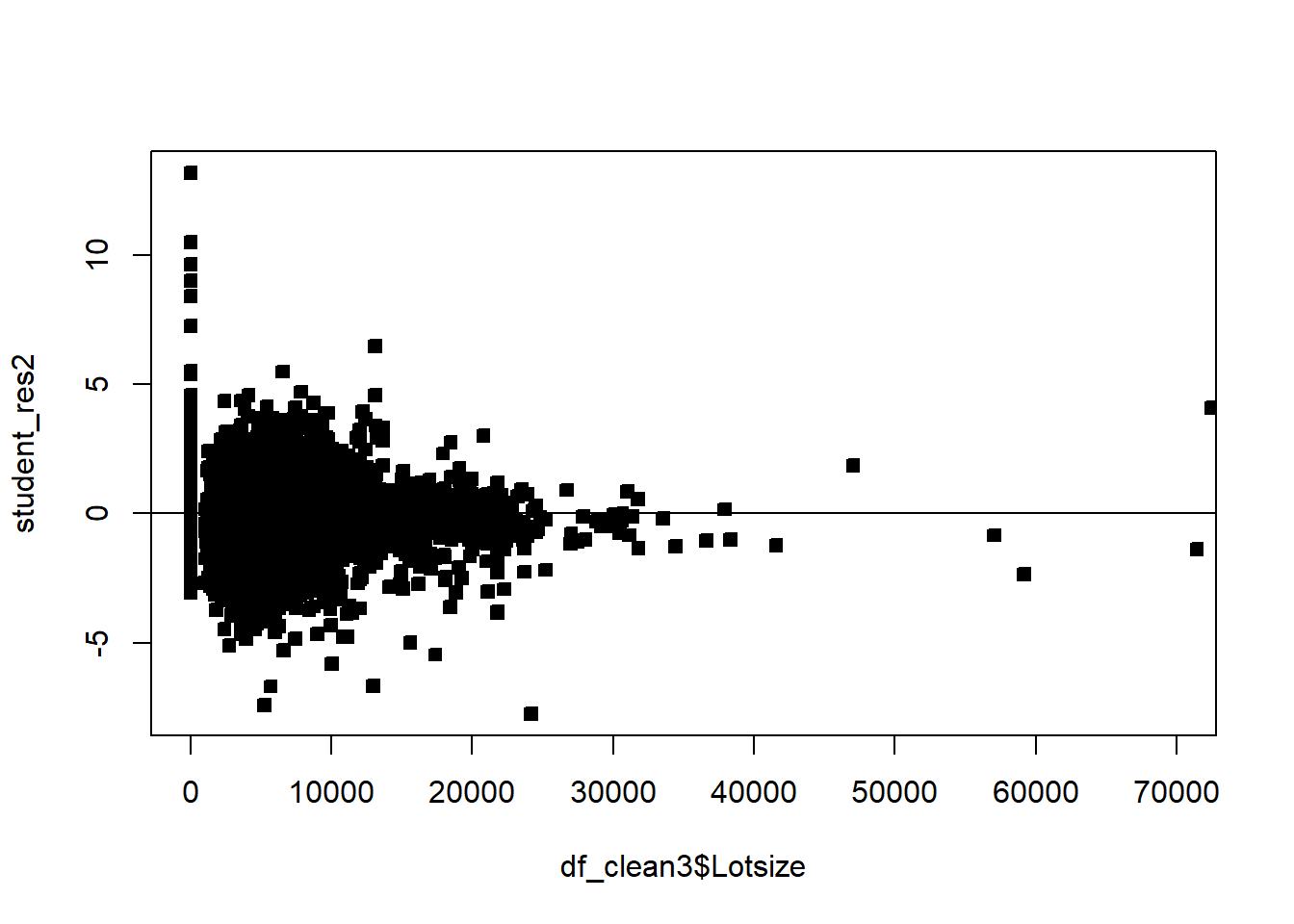
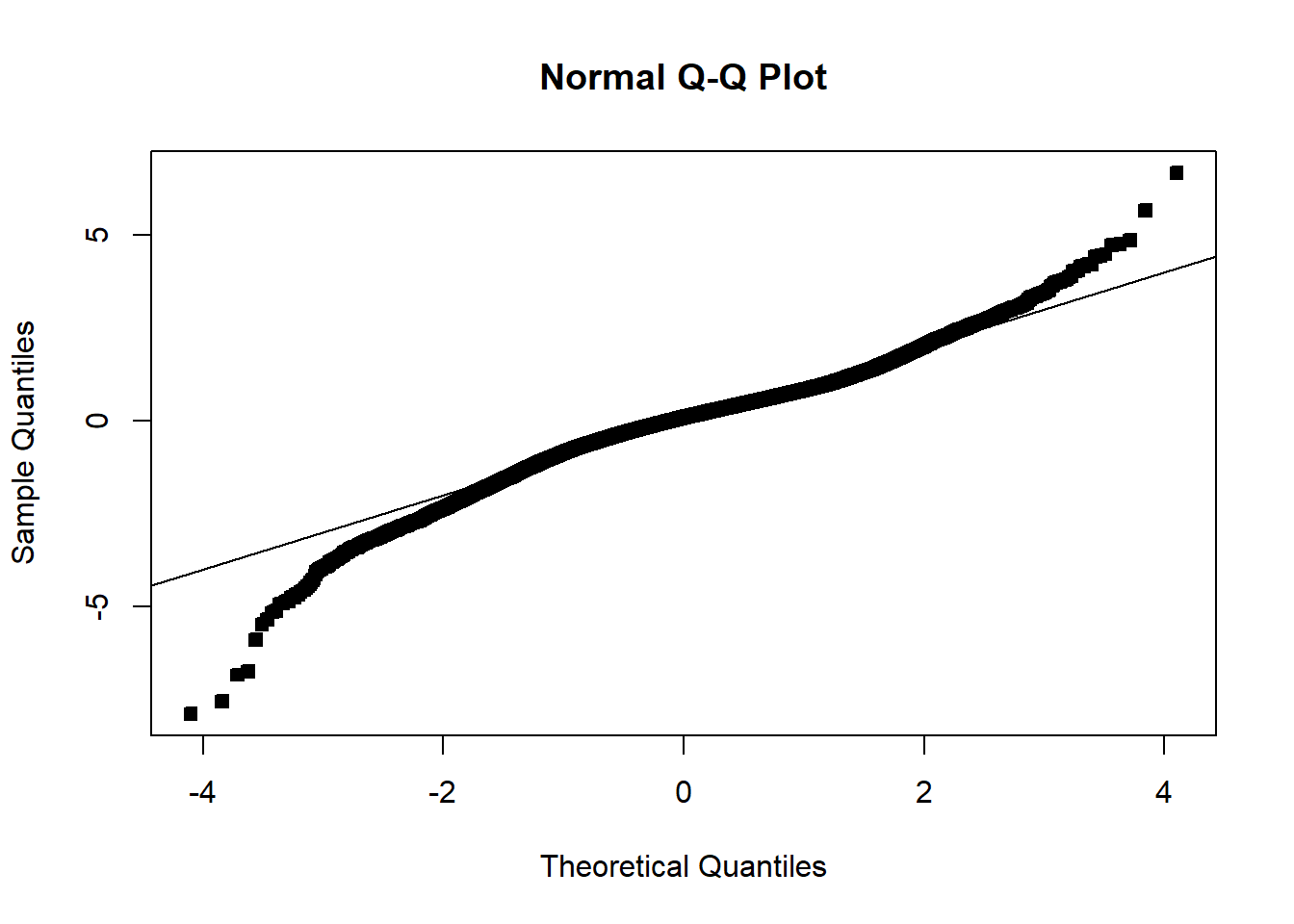
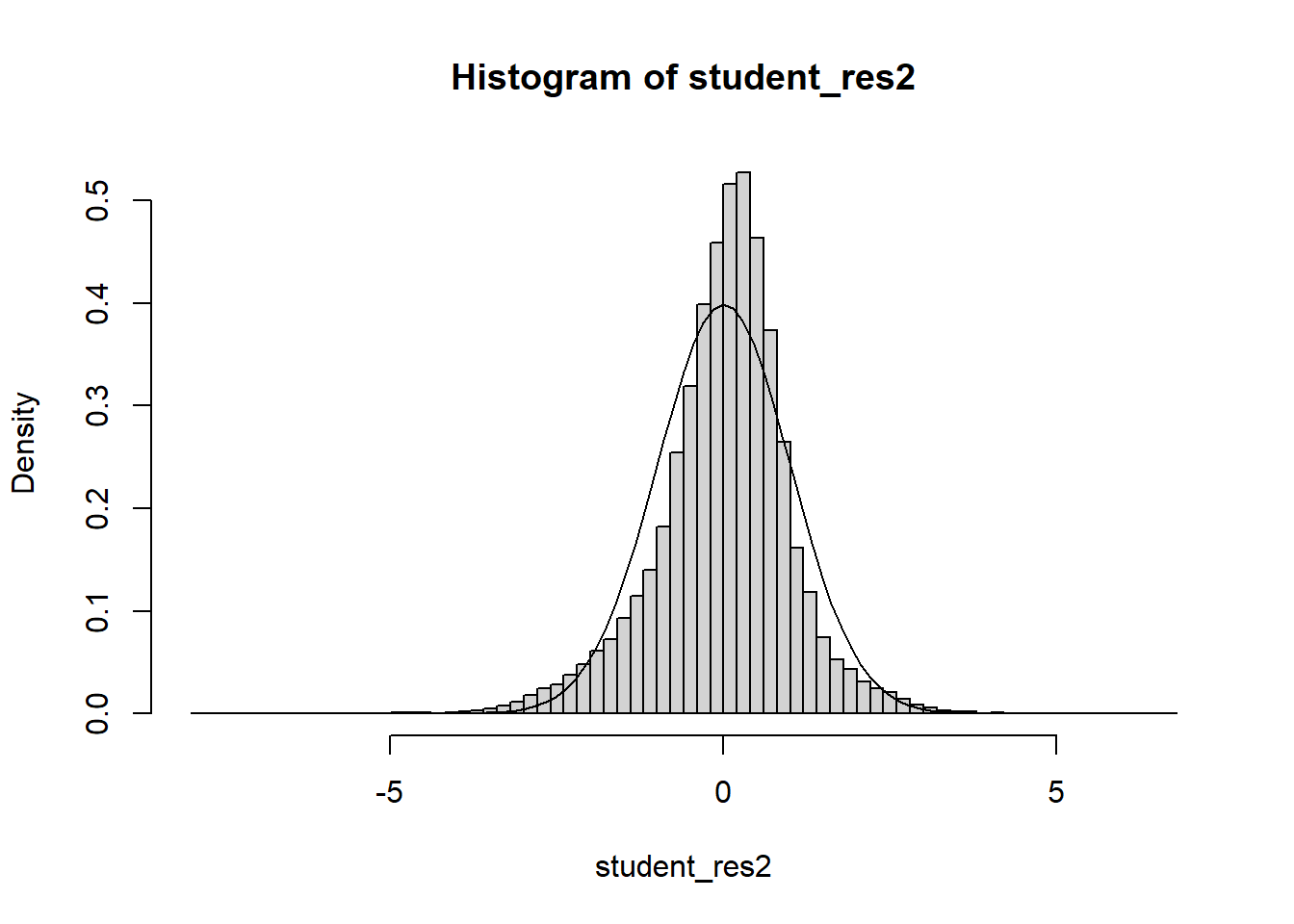
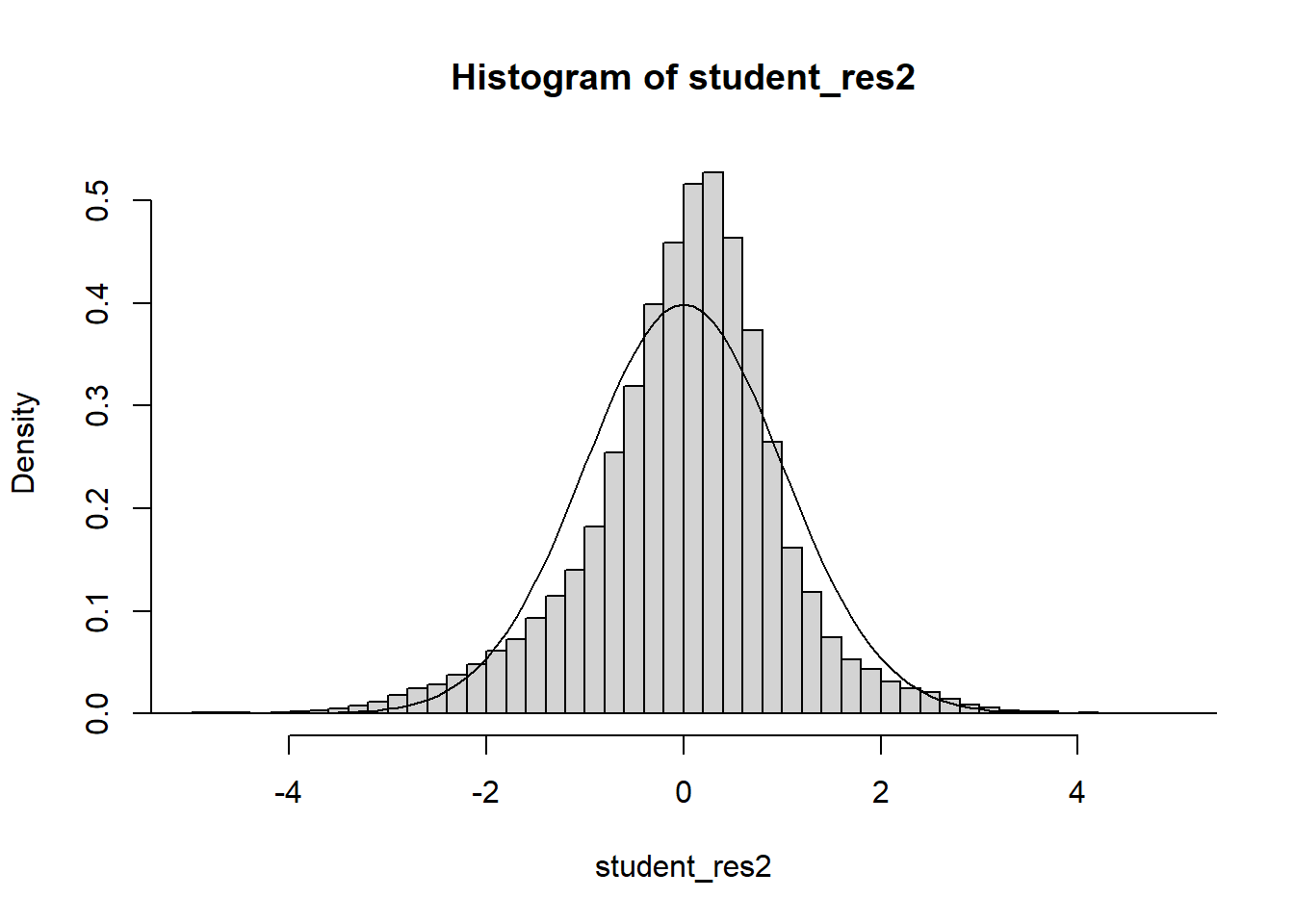
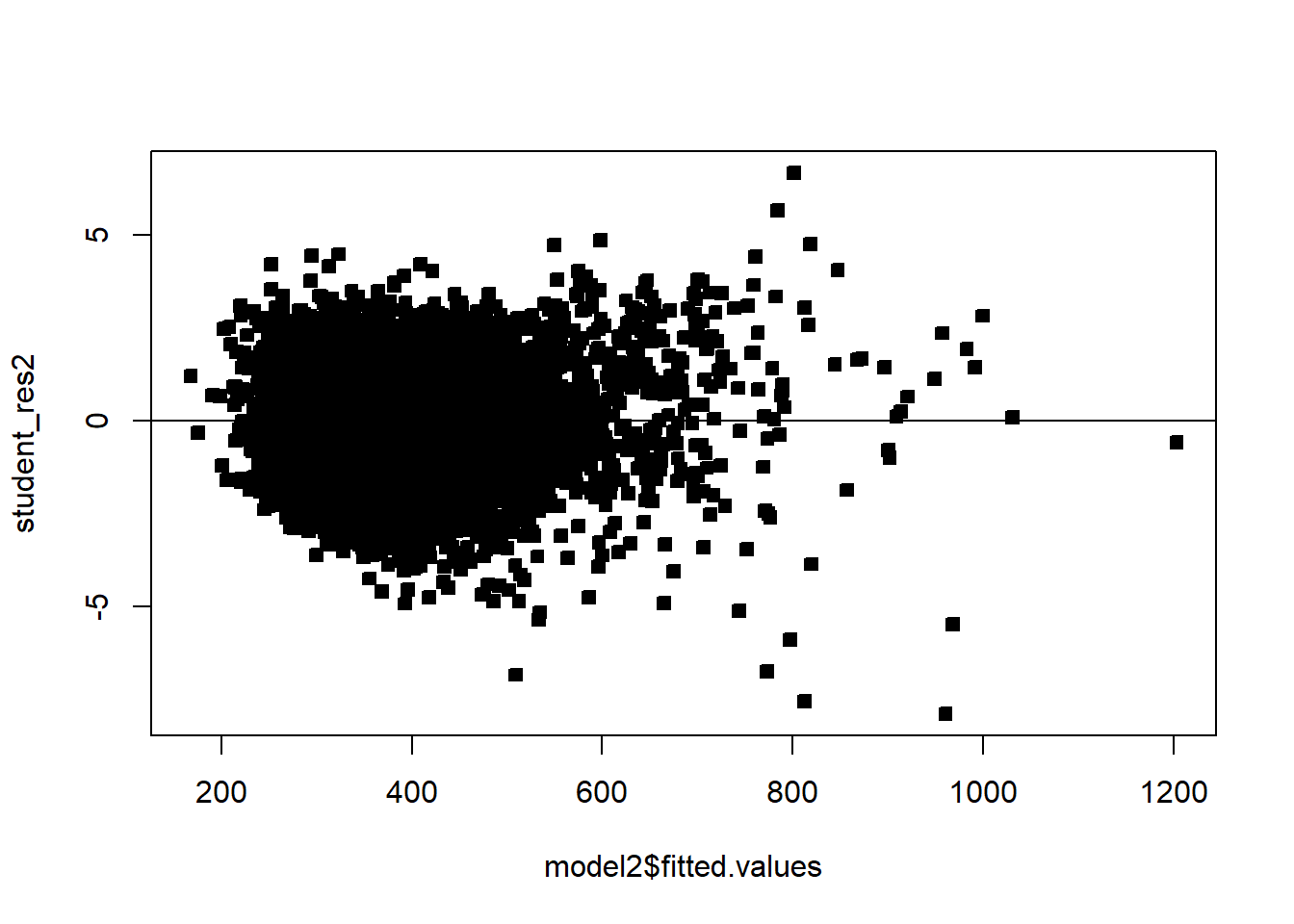
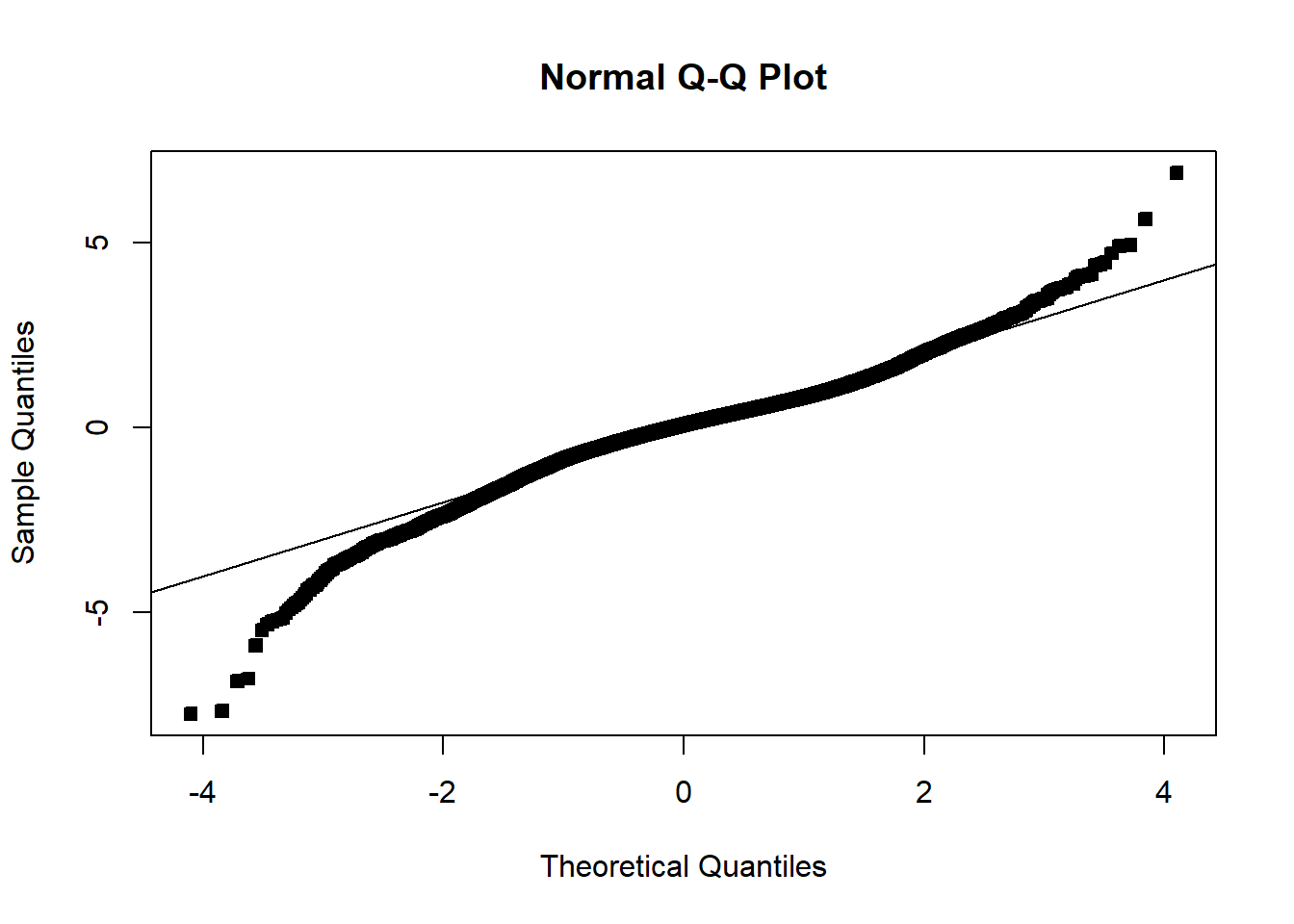
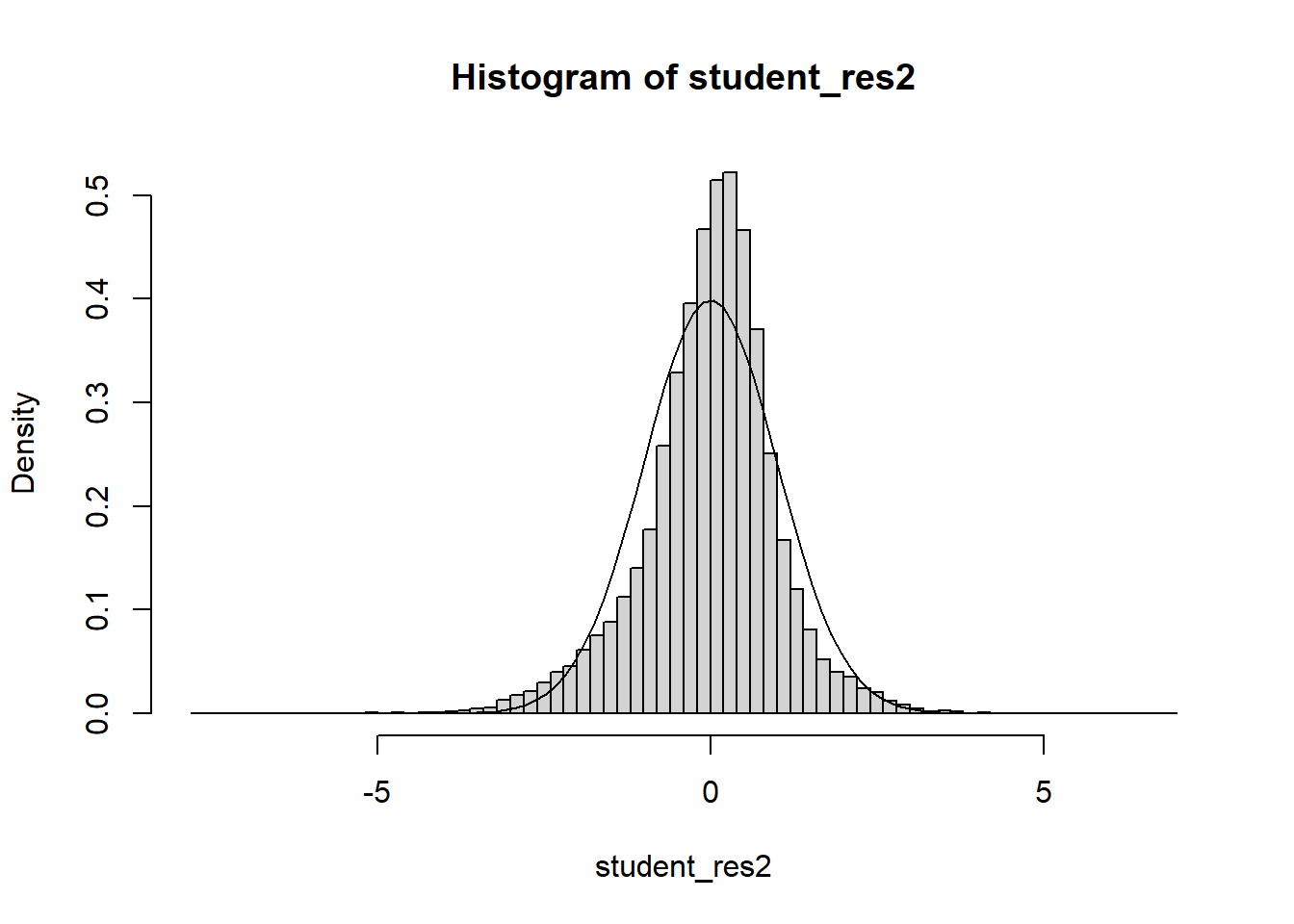
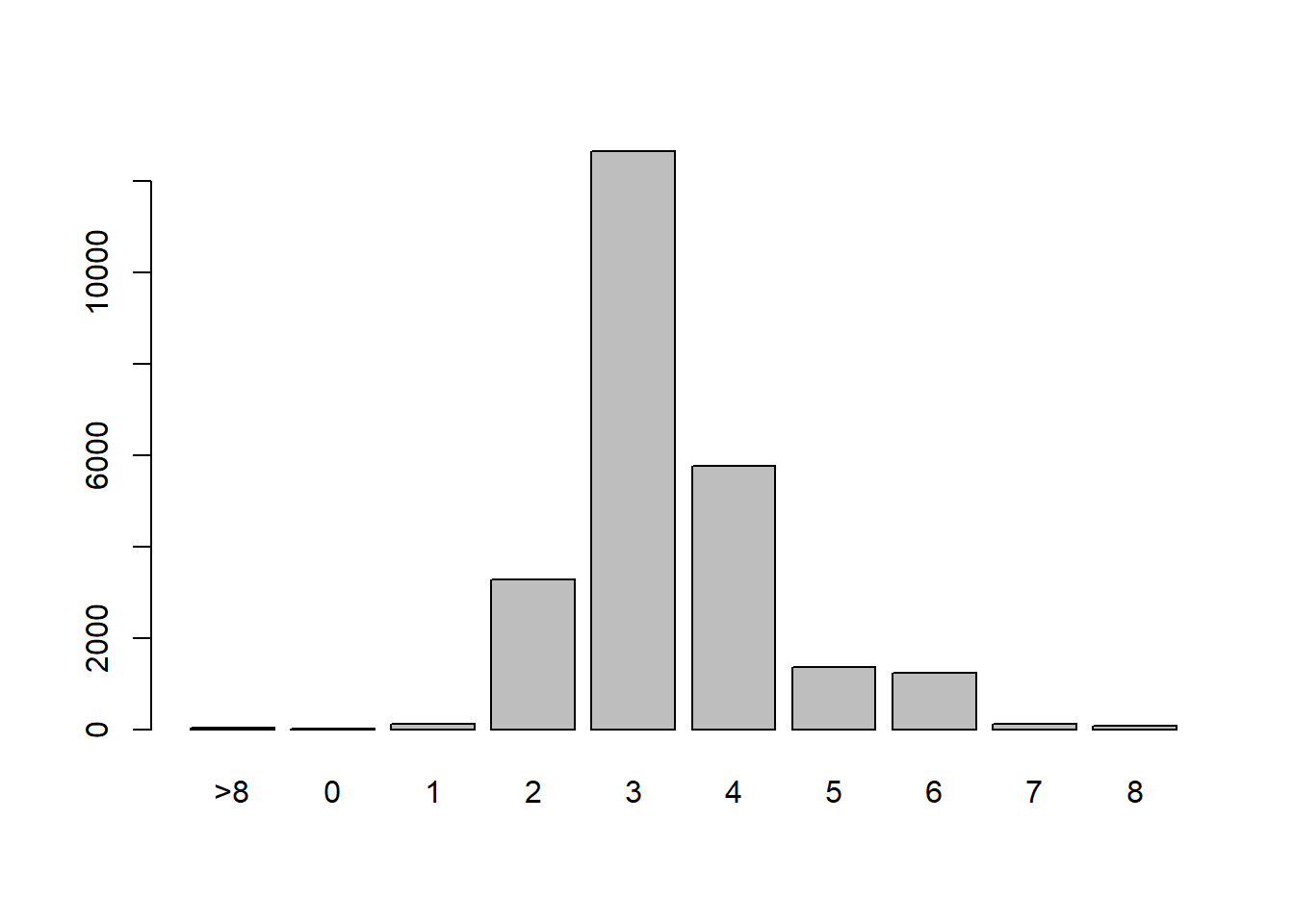Often we will have regressors that are categorical. We now discuss how to include those in a regression model. In general, categorical variables can be included in a regression model via indicator variables.
6.1 What are indicator variables?
If a regressor has two categories \(A\) and \(B\), that regressor can be included in the model as
\[\begin{equation*}
z= \begin{cases}0 & \text { if the observation is type A } \\ 1 & \text { if the observation is type B }\end{cases}
\end{equation*}\] Sometimes people choose \[\begin{equation*}
z= \begin{cases}-1 & \text { if the observation is type A } \\ 1 & \text { if the observation is type B }\end{cases}.
\end{equation*}\]
The variable \(z\) is an indicator variable. Indicator variables are in numeric form, and can therefore be included in the design matrix \(X\) in the usual way we do for continuous regressors.
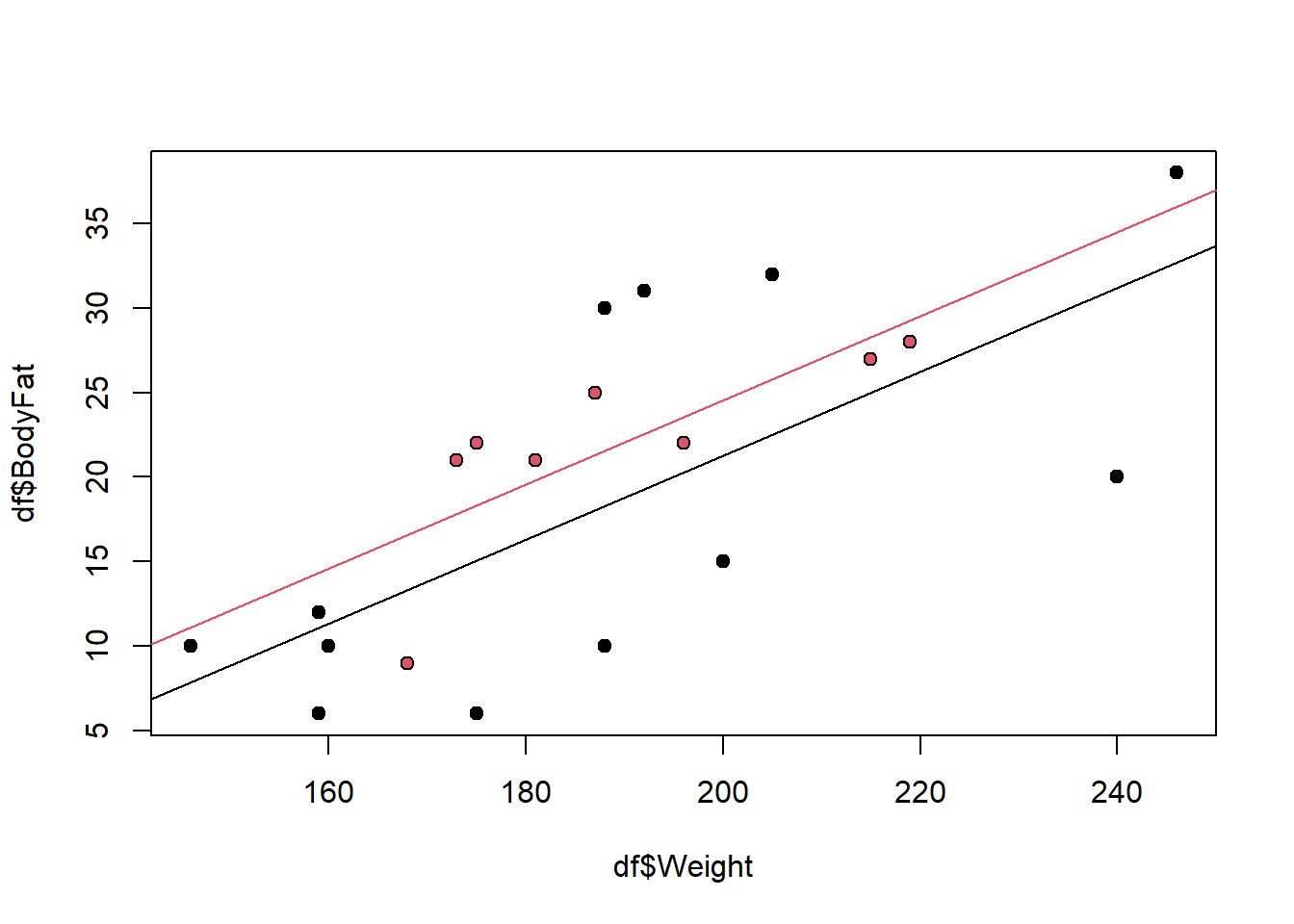
Example 6.1 Let’s recall Example 3.1 and suppose we have some new data as follows:
It is difficult to accurately determine a person’s body fat percentage without immersing them in water. However, we can easily obtain the weight of a person. A researcher would like to know if weight and body fat percentage are related? They also suspect that sex plays a role in the prediction. This researcher collected the following data:
Individual
1
2
3
4
5
6
7
8
9
10
Weight (lb)
175
181
200
159
196
192
205
173
187
188
Body Fat (%)
6
21
15
6
22
31
32
21
25
30
Sex
F
M
F
F
M
F
F
M
M
F
————
—–
—–
—–
—–
—–
—–
—–
—–
—–
—–
Individual
11
12
13
14
15
16
17
18
19
20
Weight (lb)
188
240
175
168
246
160
215
159
146
219
Body Fat (%)
10
20
22
9
38
10
27
12
10
28
Sex
F
F
M
M
F
F
M
F
F
M
Write out the appropriate indicator variable for Sex. Interpret the resulting regression equation for regressing Body fat against weight and sex. Interpret the coefficient that corresponds to the Sex variable.
We have that \[\begin{equation*}
X_{2i}= \begin{cases}0 & \text { if the subject $i$ is male } \\ 1 & \text { if the subject $i$ is female }\end{cases}.
\end{equation*}\]
The regression equation is then \[Y_i|X=\beta_0+\beta_1X_{i1}+\beta_2X_{i2}+\epsilon_i,\] where \(X_{i1}\) is the weight of individual \(i\).
When \(X_{i2}=0\), then the regression equation for males is given by \(Y_i|X=\beta_0+\beta_1X_{i1}+\epsilon_i\). Therefore, the expected body fat percentage for males is \({\textrm{E}}\left[Y_i|X\right]=\beta_0+\beta_1X_{i1}\). Additionally, when \(X_{i2}=1\), then the regression equation for females is given by \(Y_i|X=\beta_0+\beta_1X_{i1}+\beta_2+\epsilon_i\). It follows that the expected body fat percentage for females is \({\textrm{E}}\left[Y_i|X\right]=\beta_0+\beta_1X_{i1}+\beta_2\). Thus, we have that the expected body fat percentage for females is \(\beta_2\) higher than for males, holding weight constant. This is the interpretation of the coefficient for the dummy variable in this case. Observe that for males and females, the regression lines are parallel. The model says that sex accounts for a constant shift in your expected body fat, but the slope (the coefficient for weight) of the regression line remains the same.
We can generalize this idea out of this example. In the case of two categories, the interpretation of the coefficient for the dummy variable is given as follows: Holding other regressors constant, on average, the change in response attributed to the case where the dummy variable is 1, relative to the case where the dummy variable is 0, is given by the coefficient for the dummy variable.
Moving on, a regressor that has \(k\) categories can be represented by \(k-1\) indicator variables:
\(x_1\)
\(x_2\)
\(\ldots\)
\(x_{k-1}\)
Category
0
0
\(\ldots\)
0
1
1
0
\(\ldots\)
0
2
0
1
\(\ldots\)
0
3
\(\vdots\)
\(\vdots\)
\(\ldots\)
\(\vdots\)
\(\vdots\)
0
0
\(\ldots\)
1
\(k\)
In this case, the category, or level, where all dummy variables are equal to 0 is the reference category. The reference category is the baseline we will compare all other categories to. You may want to choose this carefully. In this case, the interpretation of each of the \(k-1\) coefficients is going to be as follows: Holding other regressors constant, on average, the change in response attributed to the case where the dummy variable corresponding to the coefficient is 1, relative to the reference category, is given by the coefficient for the dummy variable. Note that the reference category has no variable associated with it.
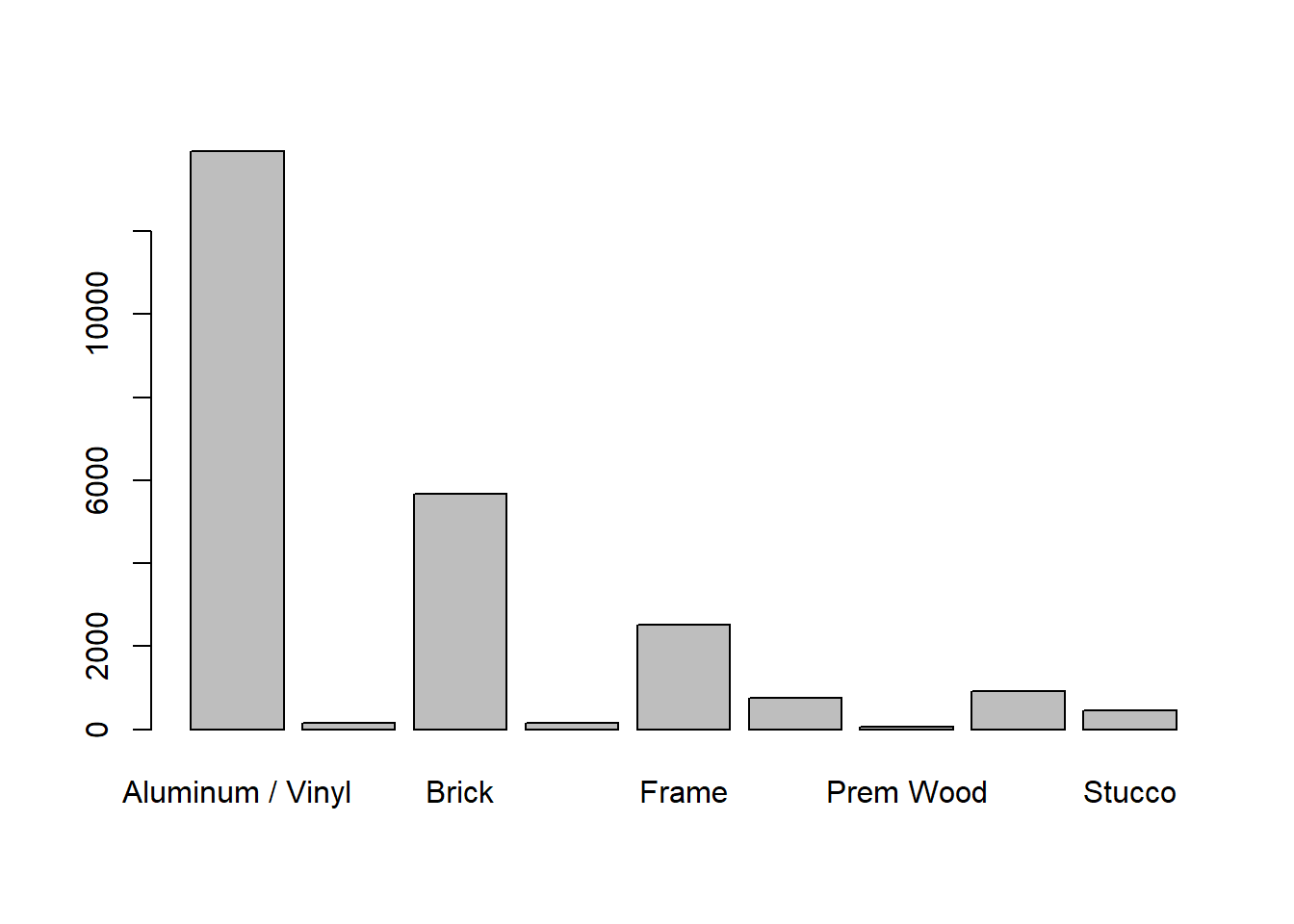
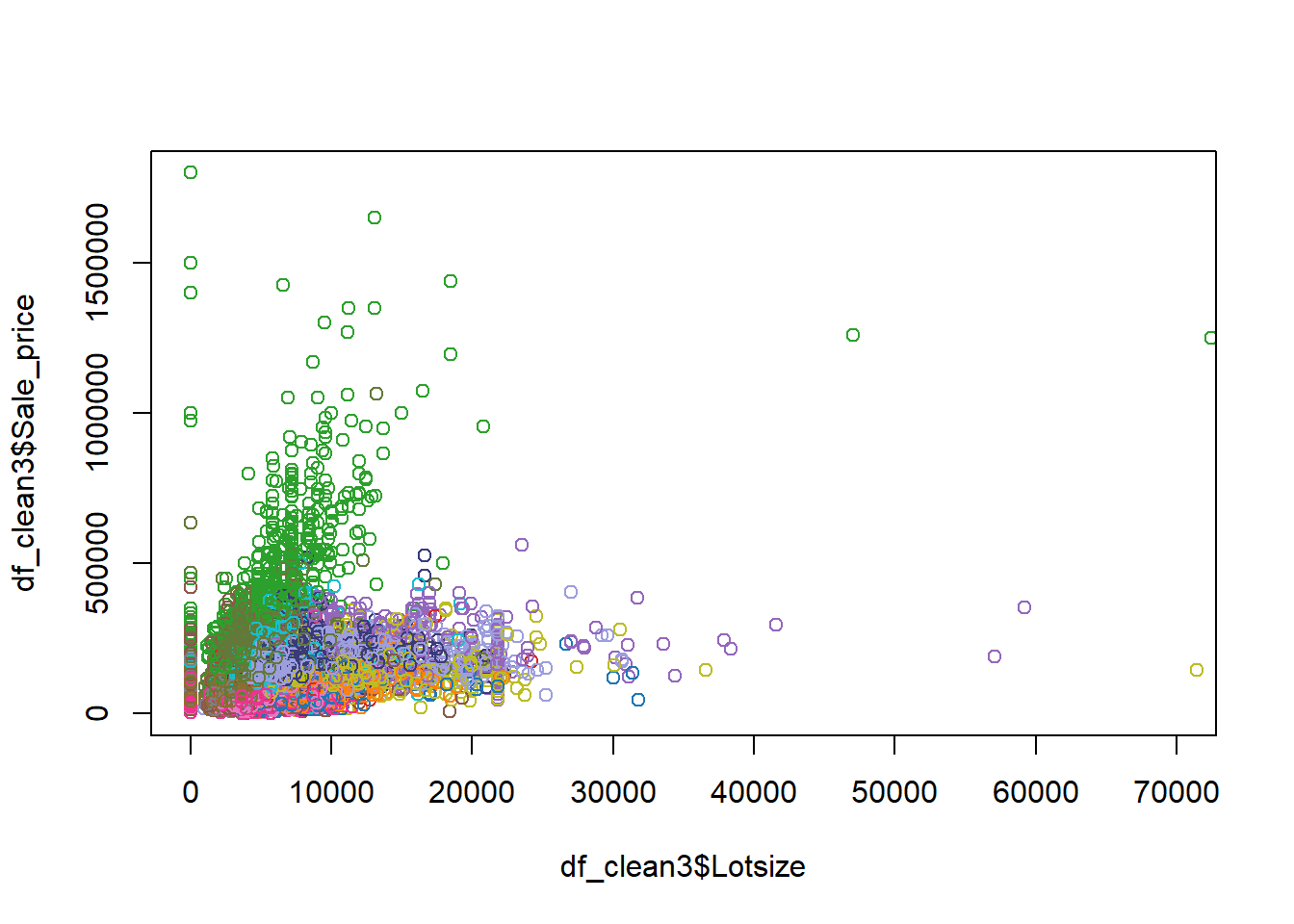
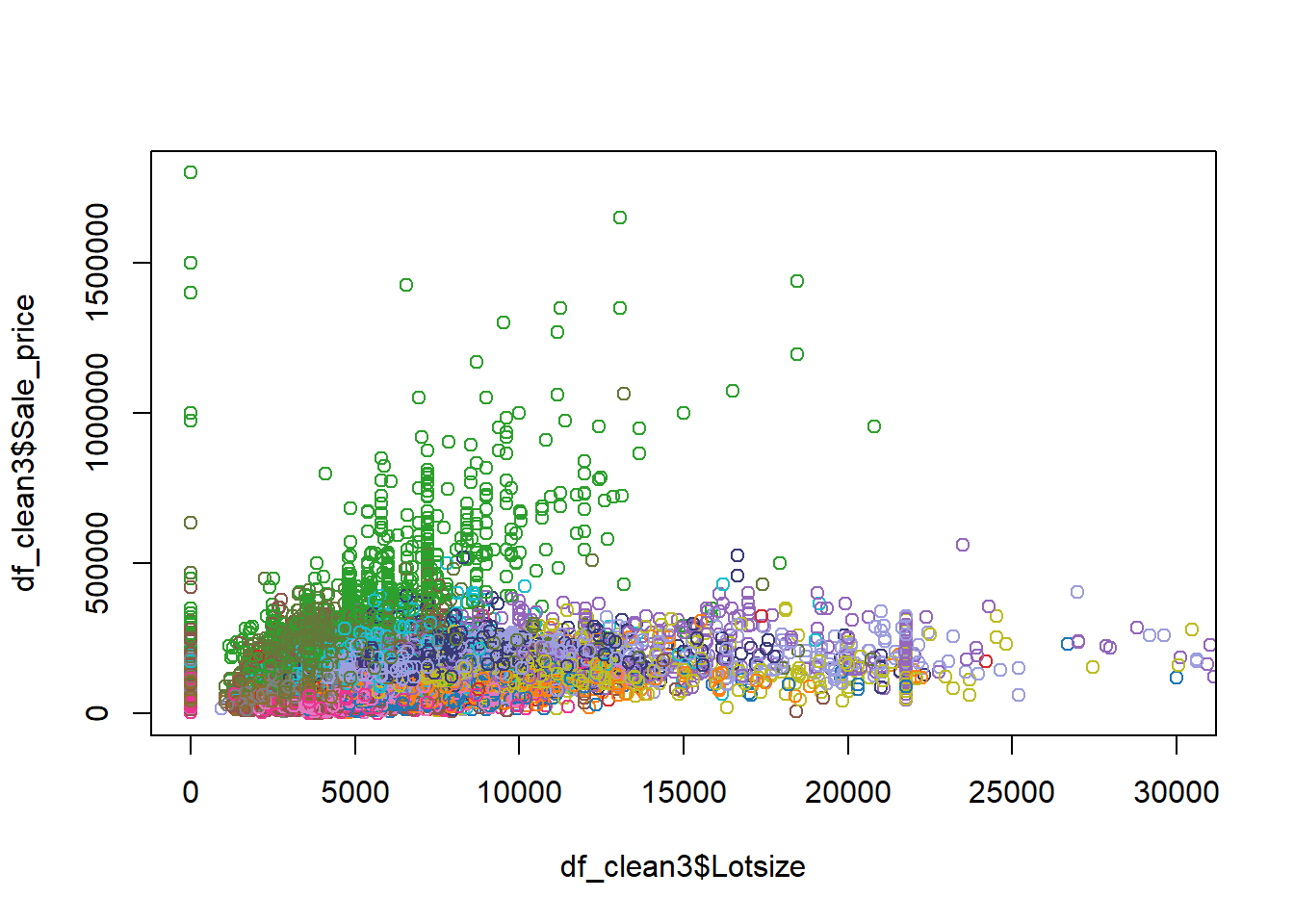
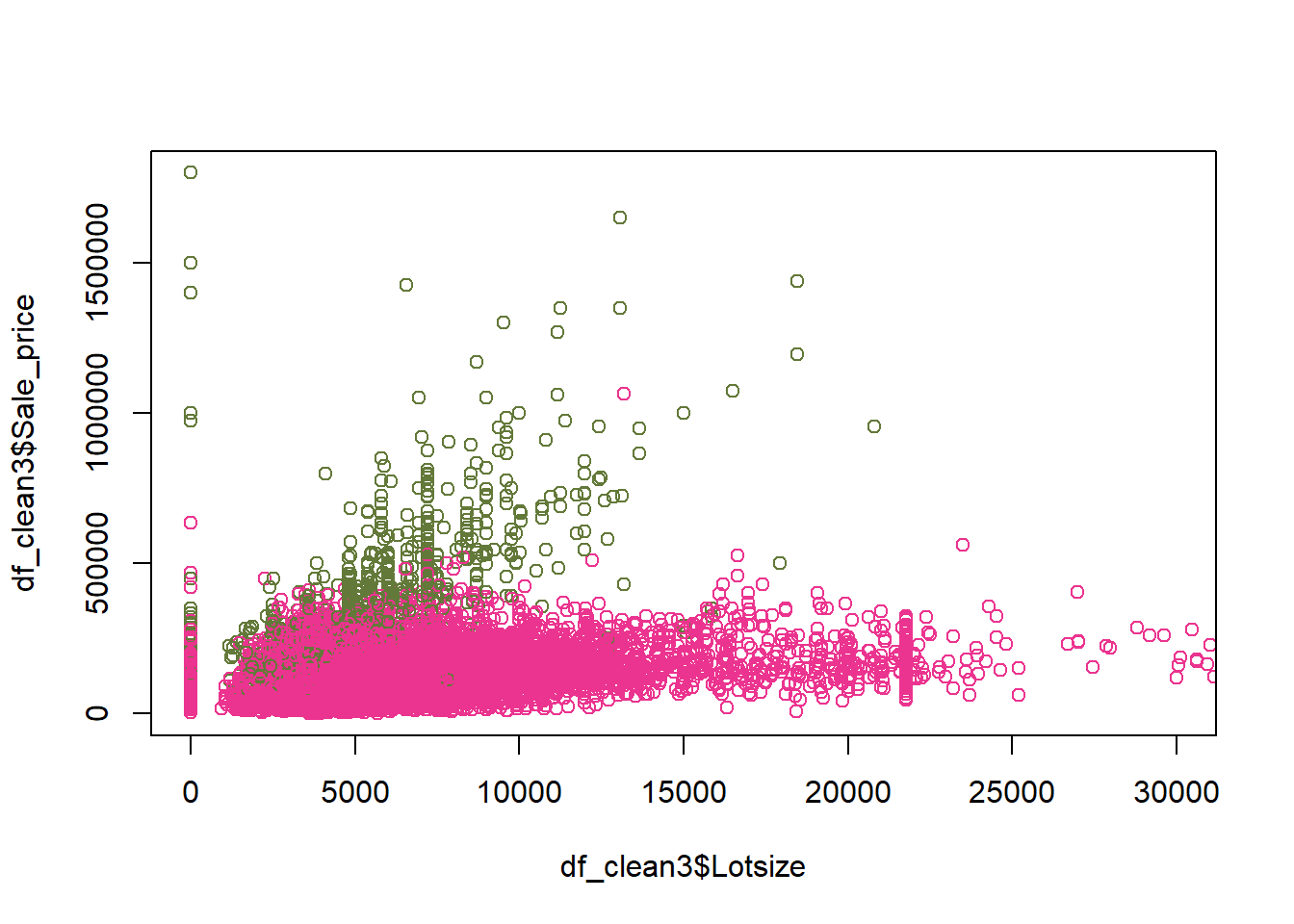
Example 6.2 When evaluating factors that affect the price of real estate, we may wish to consider location, while adjusting for lot size, year built and finished square feet. The data set clean_data.csv contains the prices of various types of real estate, as well as several important regressors. Regress the sale price on location, lot size, year built and finished square feet. Interpret the coefficient related to District 14. According to the model, holding other variables constant, what district has the highest priced properties? the lowest? Observe that District 7 has a non significant coefficient. In this case, what does it mean for District 7 to have a coefficient of 0?
Warning: package 'lubridate' was built under R version 4.5.2
Attaching package: 'lubridate'
The following objects are masked from 'package:base':
date, intersect, setdiff, union
# Example: We would like to see how sale price of a home is related to# various factors####### Loading data ##############df_clean2=read.csv('clean_data.csv',stringsAsFactors = T)df_clean2$District=as.factor(df_clean2$District)# The first level is the reference categoryattributes(df_clean2$District)$levels[1]
[1] "1"
####### Fitting the model ##############model=lm(Sale_price~District+Fin_sqft+Lotsize+Year_Built,df_clean2)summ=summary(model); summ
Interpret the coefficient for District 14: Holding lot size, finished square feet and year built constant, on average, the change in the price of a property in District 14, relative to District 1, is 102 600.
According to the model, holding other variables constant, what district has the highest priced properties on average? the lowest? The highest coefficient is District 3, and it is positive, so,holding other variables constant, on average District 3 has the highest priced properties. The lowest coefficient is District 4, and it is negative, so, holding other variables constant, on average District 4 has the lowest priced properties.
Observe that District 7 has a non significant coefficient. In this case, what does it mean for District 7 to have a coefficient of 0? This means that there is not enough evidence to show that District 1 and District 7 have different prices, holding other variables constant, on average.
Note
If all coefficients for the dummy variables are positive, then the reference category has the lowest average value of the response. Analogously, if all coefficients for the dummy variables are negative, then the reference category has the highest average value of the response. Why? Use the interpretation of the coefficients to answer this question.
Note
ANOVA is Regression!- In one-way ANOVA, recall that we test for a difference in group means for a continuous response. We can represent the treatment groups with dummy variables and view this as a regression problem. That is, regressing the outcome on the dummy variables. It turns out that the regression ANOVA, that is, the overall \(F\)-test, applied to these dummy variables is equivalent to the one-way ANOVA (see Section 8.3 of the textbook.)
6.2 Interaction effects
An interaction effect occurs when the effect of one regressor on the response depends on the value of another regressor. In other words, the combined effect of two variables is not simply additive; the value of one variable modifies the impact of the other. In linear regression, this means that the coefficient of one regressor depends on the other.
We now give a simple example:
Suppose we are studying the effect of hours studied (\(X_1\)) and attendance (\(X_2\)) on exam scores (\(Y\)). An interaction effect between \(X_1\) and \(X_2\) would imply that the effect of studying on exam scores is different depending on the level of attendance. This can be modeled by including an interaction term (\(X_1 \times X_2\)) in the regression equation:
The coefficient \(\beta_3\) represents the interaction effect between X1 and X2. For instance, if \(\beta_3>0\), then the more the student has attended the course, the more beneficial the student’s hours studied will be.
Some examples of how interaction effects are applied in real life are given by:
Psychology: Studying how different treatments and demographic factors interact to influence behavior.
Marketing: Analyzing how different marketing strategies and customer demographics interact to affect sales.
Medicine: Investigating how different drugs and patient characteristics interact to affect health outcomes.
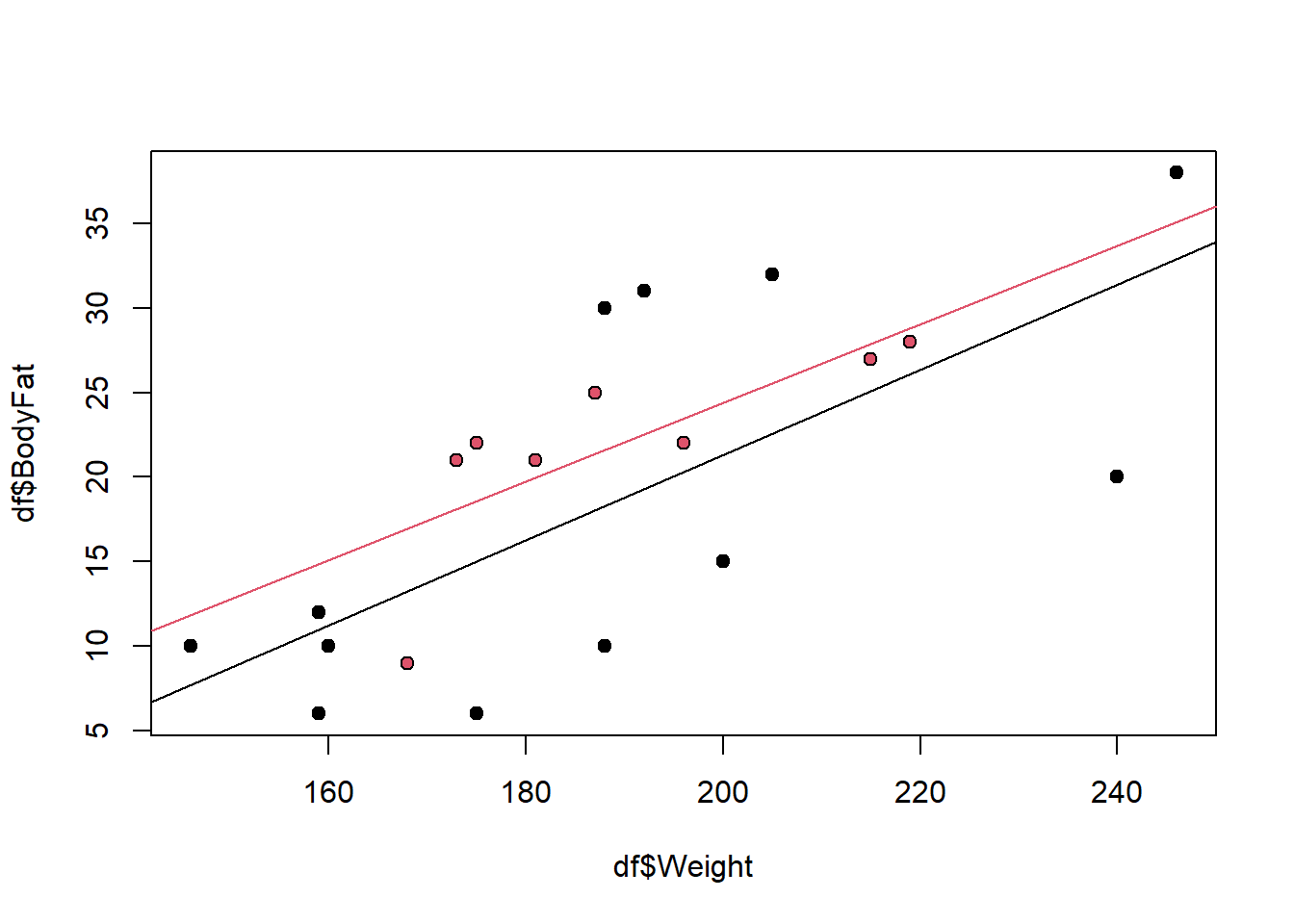
Example 6.3 Let’s recall Example 6.1 and suppose the researcher would like you to include the interaction effect between Weight and Sex. Explain how the regression line changes with a non-zero interaction effect. Interpret the estimated interaction effect. Is it significant?
The regression equation is \[Y_i|X=\beta_0+\beta_1X_{i1}+\beta_2X_{i2}+\beta_3X_{i1}X_{i2}+\epsilon_i.\] If \(\beta_3\neq 0\) then we proceed as follows. When \(X_{i2}=0\), then the regression equation for males is still given by \(Y_i|X=\beta_0+\beta_1X_{i1}+\epsilon_i\). Therefore, the expected body fat percentage for males is \({\textrm{E}}\left[Y_i|X\right]=\beta_0+\beta_1X_{i1}\). Additionally, when \(X_{i2}=1\), then the regression equation for females is given by \[Y_i|X=\beta_0+\beta_1X_{i1}+\beta_2+\beta_3X_{i1}+\epsilon_i=\beta_0+(\beta_1+\beta_3)X_{i1}+\beta_2+\epsilon_i.\] It follows that the expected body fat percentage for females is \({\textrm{E}}\left[Y_i|X\right]=\beta_0+(\beta_1+\beta_3)X_{i1}+\beta_2\). Thus, adding an interaction effect allows the model to generate a completely different regression line, that is a different slope and intercept for females. The expected body fat percentage for females is then \(\beta_2+\beta_3X_{i1}\) higher than for males, holding weight constant. Adding an interaction effect allows the slope to also vary, depending on whether the subject is male or female.
Notice how the slopes of the regression lines differ! Now, the estimated interaction effect is 0.01987. Let’s interpret it. We have that, on average, for every one lb increase in weight, the body fat percentage of a female increases by 0.01987 more than that of a male.
(In this case, the term is not significant, so we would probably drop it.)
Note
We can include interaction effects in the regression model in R by adding variable_1*variable_2 to the right-hand side of the formula equation.
Example 6.4 When evaluating factors that affect the price of real estate, we may wish to consider location, while adjusting for lot size, year built and finished square feet. The data set clean_data.csv contains the prices of various types of real estate, as well as several important regressors. Regress the sale price on location, lot size, year built and finished square feet. Add an interaction term between year built and location. Interpret the interaction term for District 14.
####### Fitting the model ##############model=lm(Sale_price~District+Fin_sqft+Lotsize+Year_Built+Year_Built*District,df_clean2)summ=summary(model); summ
Observe that the interaction term between year built and District 14 is -723.1$. In addition, note that year built has a positive coefficient of 785$. We can interpret the interaction effect as follows: Holding finished square feet and lot size constant, a one year increase in year built for a home in District 14 results in an increase in price that is \(723.1\) lower than that of District 1. We can also reword this to make it a little more clear - Holding finished square feet and lot size constant, a one year increase in year built for a home in District 1 results in an increase in price that is \(723.1\) higher than that of District 14.
To see this observe that for a one unit increase in year built in District 14, we have that the price goes up by 785.0-723.1=61.9 on average, holding other variables constant. On the other hand, in District 1, the price goes up by 785.0 on average, holding other variables constant. Therefore, in general, newer homes are much more valuable in District 1.
Exercise 6.1 Interpret the main effects and the interaction effect with year built for Districts 2-4. (The main effects are the coefficients for Districts 2-4.)
Warning
Including interaction effects changes the interpretation of the main effects. When a variable is involved in an interaction term, its main effect no longer represents its overall marginal association with the response. Instead, the main effect must be interpreted at the level where the interacting variable is equal to 0 (i.e., at the reference or baseline value used in the model).
Note: Including interaction effects changes how we interpret the main effects.
When a variable is involved in an interaction term, its main effect no longer represents its overall marginal association with the response. Instead, the main effect is interpreted at the level where the interacting variable equals 0 (the baseline level used in the model).
where ProgramStats = 1 for Stats students and 0 for the baseline group (Math students).
This model includes an interaction between StudyHours and Program.
Interpretation of \(\beta_1\) (main effect of StudyHours): \(\beta_1\) is not the overall effect of increasing StudyHours.
It is the effect only for Math students, because Math is coded as 0 for ProgramStats.
In other words, \(\beta_1\) is the slope of StudyHours when ProgramStats = 0.
Interpretation of \(\beta_2\) (main effect of ProgramStats): \(\beta_2\) is not the overall difference between Stats and Math students.
It compares Stats vs. Math when StudyHours = 0, because the interaction term equals 0 at StudyHours = 0.
This example shows that once an interaction is included, the main effects must be interpreted at the point where the other interacting variable is 0.
Warning
The interpretation for interaction effects is difficult and nuanced. Make sure you study this topic carefully.
6.3 Increasing codes and quantitative regressors via dummy variables
Another approach to the treatment of a qualitative variable in regression is to measure the levels of the variable by an allocated code. Suppose we model the effect of the number of bedrooms on real estate price by its numerical value, instead of categorical value. Let’s see what happens to the regression equation. In general, ordinal variables may be better represented by dummy variables/indicators - however, dummy variables increase the complexity of the model, which we may not have enough data to support, and could lead to overfitting.
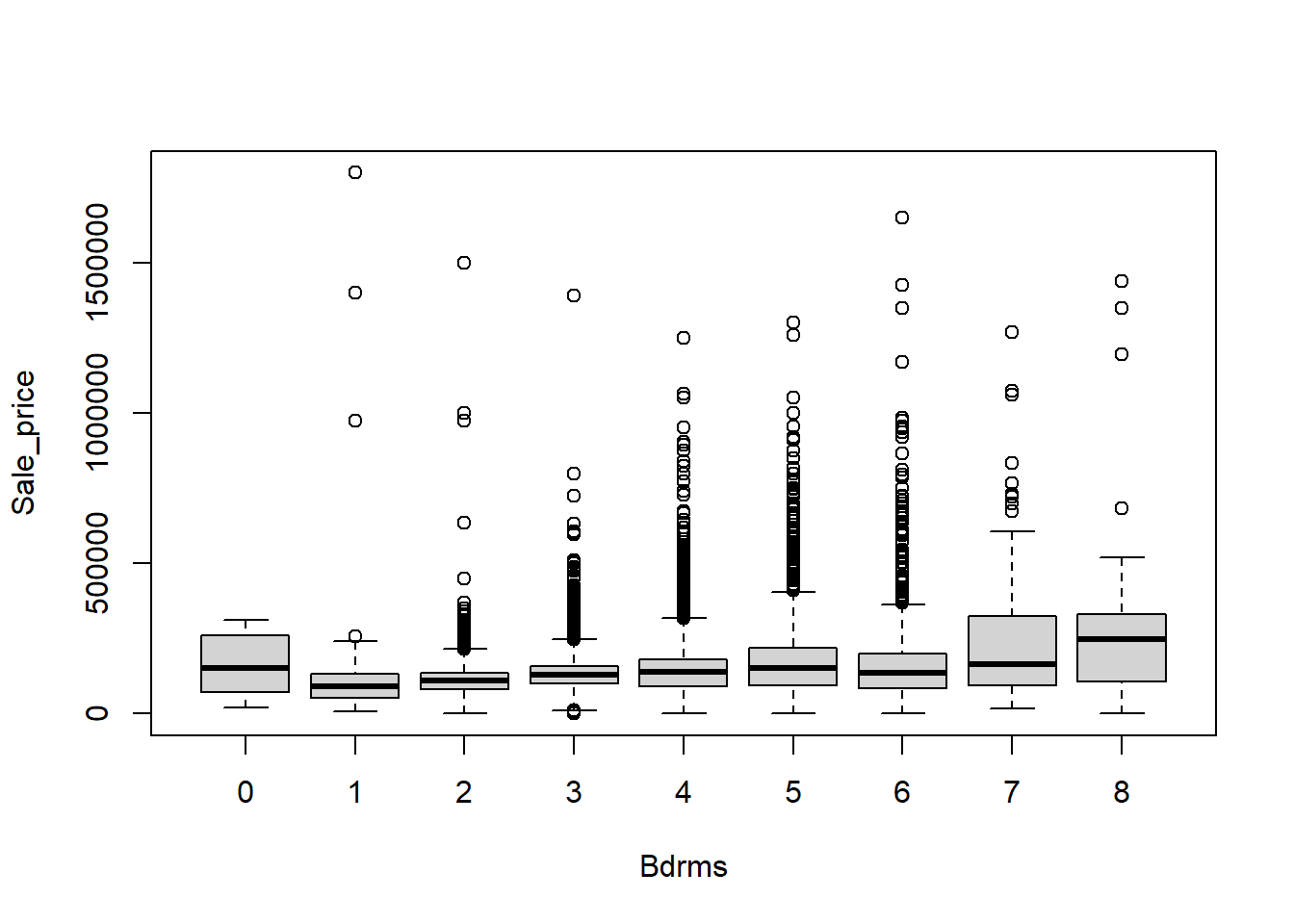
Example 6.5 When evaluating factors that affect the price of real estate, we may wish to consider the unadjusted effect of the number of bedrooms. Regress the sale price on number of bedrooms treating number of bedrooms as a continuous variable. Then, regress the sale price on number of bedrooms treating number of bedrooms as a categorical variable. Compare and contrast the two models, and the resulting fits.
####### Fitting the model ##############unique(df_clean2$Bdrms)
# Drop these rowsdf_clean3=df_clean2[df_clean2$Bdrms!='>8',]df_clean3$Bdrms=droplevels(df_clean3$Bdrms)df_clean3$Bdrms=relevel(df_clean3$Bdrms,"0")# Add new continuous variabledf_clean3$Bdrms2=as.numeric(df_clean3$Bdrms)-1boxplot(Sale_price~Bdrms,df_clean3)
Call:
lm(formula = Sale_price ~ Bdrms2, data = df_clean3)
Residuals:
Min 1Q Median 3Q Max
-224144 -43153 -6651 26849 1705343
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 76159.0 1849.3 41.18 <2e-16 ***
Bdrms2 18498.1 522.4 35.41 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 84540 on 24593 degrees of freedom
Multiple R-squared: 0.04851, Adjusted R-squared: 0.04847
F-statistic: 1254 on 1 and 24593 DF, p-value: < 2.2e-16
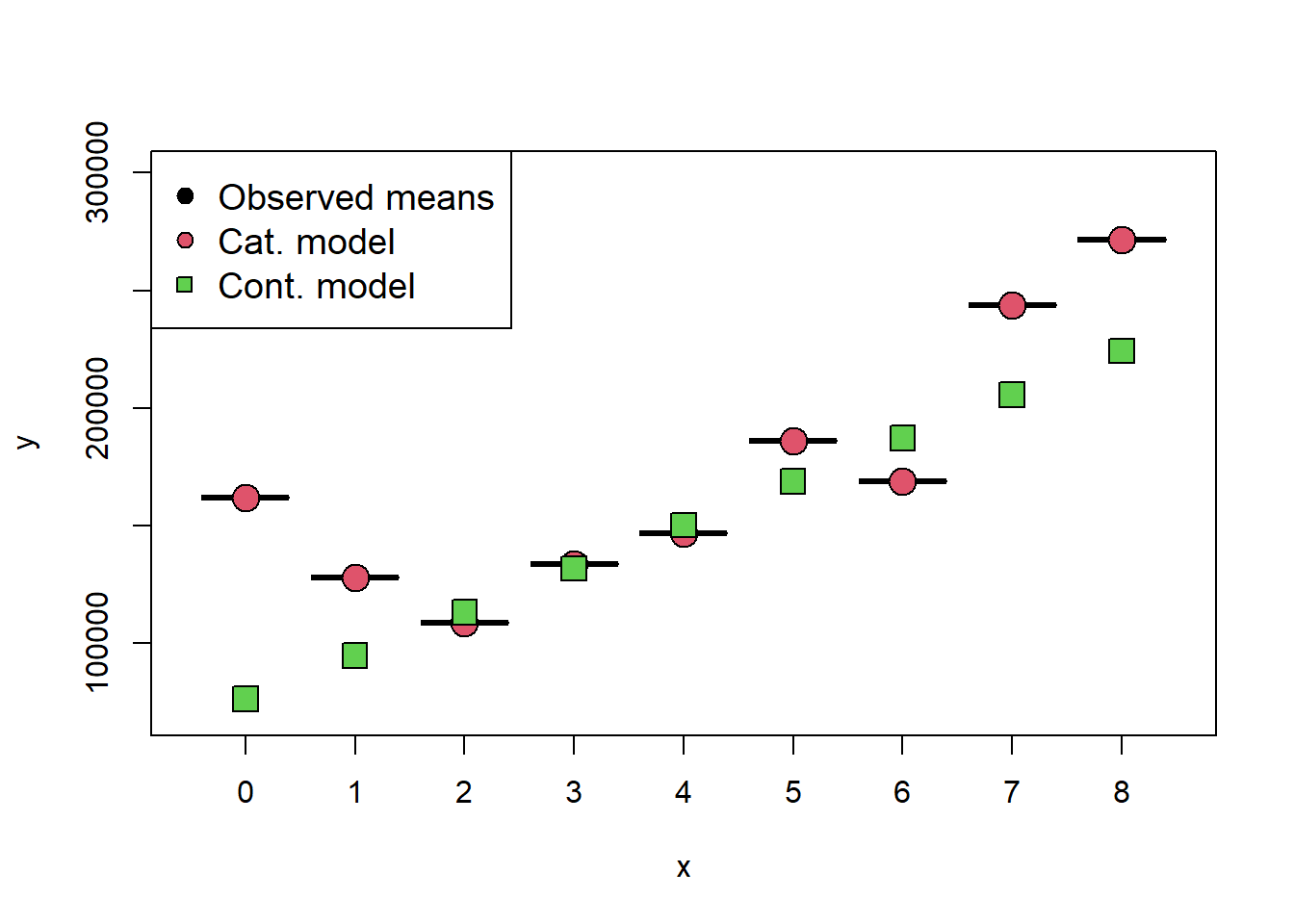
Observe that the continuous model says that for every additional bedroom, on average the price increases by 18 498$. On the other hand, the categorical model says that the change in price depends on the number of bedrooms. For example, going from 0 bedrooms to 1 bedroom, we actually see a reduction in price of -33 909$. Let’s graph the expected price for each number of bedrooms from both models:
####### Fitting the model ##############new_dat=data.frame('Bdrms'=sort(unique(df_clean3$Bdrms)))new_dat2=data.frame('Bdrms2'=0:8)# predict(model_ca,new_dat)# predict(model_co,new_dat2)observed_means=aggregate(Sale_price~Bdrms,data=df_clean3, FUN ="mean")plot(observed_means[,1],observed_means[,2],pch=25,bg=1,cex=3,ylim=c( 70000,300000))points(x=observed_means[,1],predict(model_ca,new_dat),pch=21,bg=2,cex=2)points(x=observed_means[,1],predict(model_co,new_dat2),pch=22,bg=3,cex=2)legend("topleft",legend=c("Observed means","Cat. model","Cont. model"),pch=c(21,21,22),pt.bg=c(1,2,3),cex=1.2)
Observe that the continuous model does not match the data at all, while the categorical model is able to model the non-linear relationship between the number of bedrooms and the sale price! Why is this the case? Treating a regressor as continuous implies that there is a linear relationship between that regressor and the response. On the other hand, modelling the variable with indicators does not place any assumption on the relationship between the regressor and the response. The drawback, is that we need 7 more parameters in the model.
Warning
When deciding to treat continuous or ordinal variables as continuous, it is critical that you evaluate whether it is acceptable to assume a linear relationship between the regression and the response. If you cannot verify this assumption, or it seems invalid, it is best to treat the regressor as categorical.
Quantitative regressors can also be represented by indicator variables. Sometimes this is necessary because it is difficult to collect accurate information on the quantitative regressor, or the exact values are obscured for privacy reasons. Treating a quantitative factor as a qualitative one increases the complexity of the model. This approach also reduces the degrees of freedom for error. However, the indicator variable approach does not require the analyst to make any prior assumptions about the functional form of the relationship between the response and the regressor variable, as previously discussed.
6.4 A larger scale example
It is a good time to stop introducing new material and do a larger scale example.
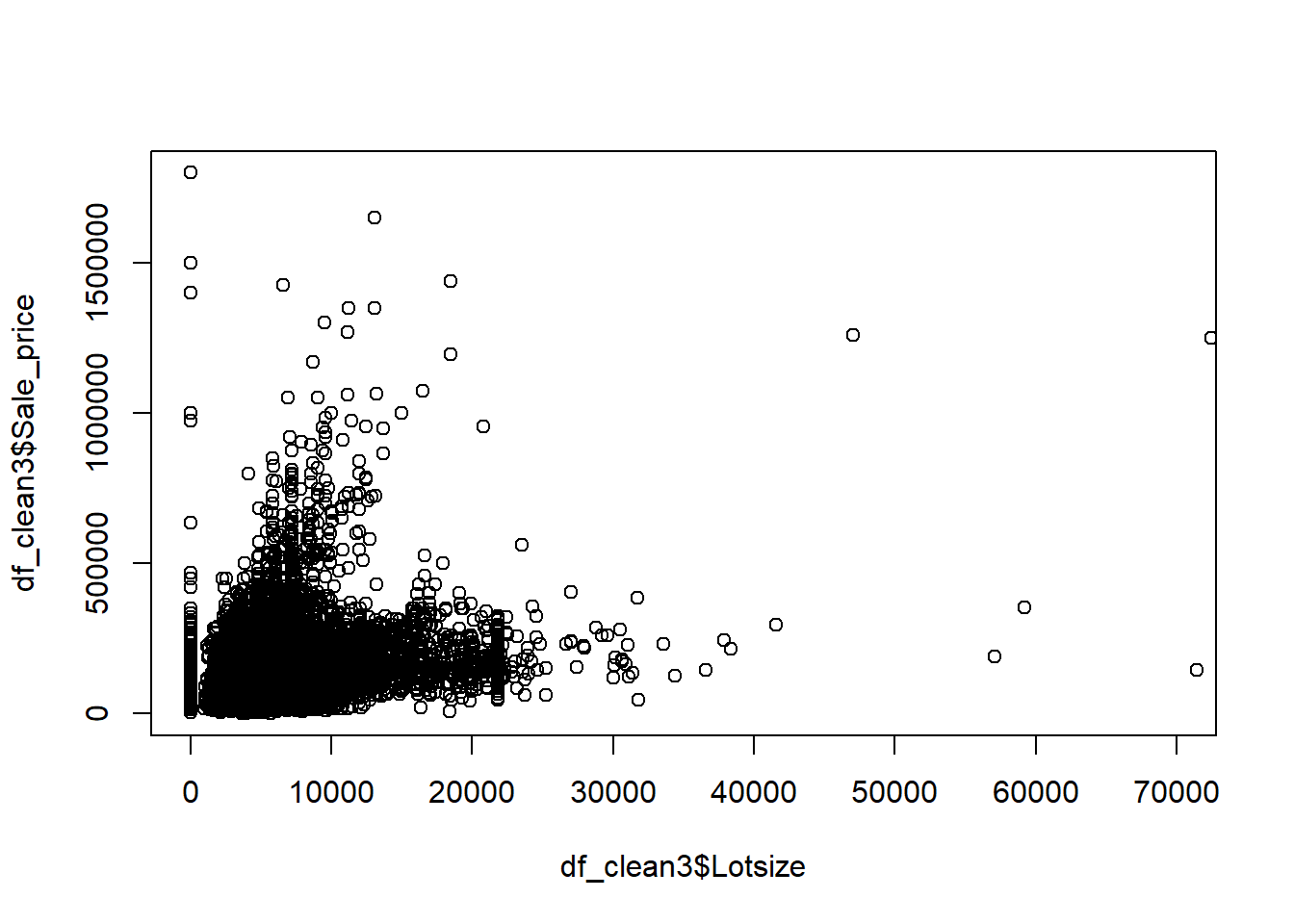
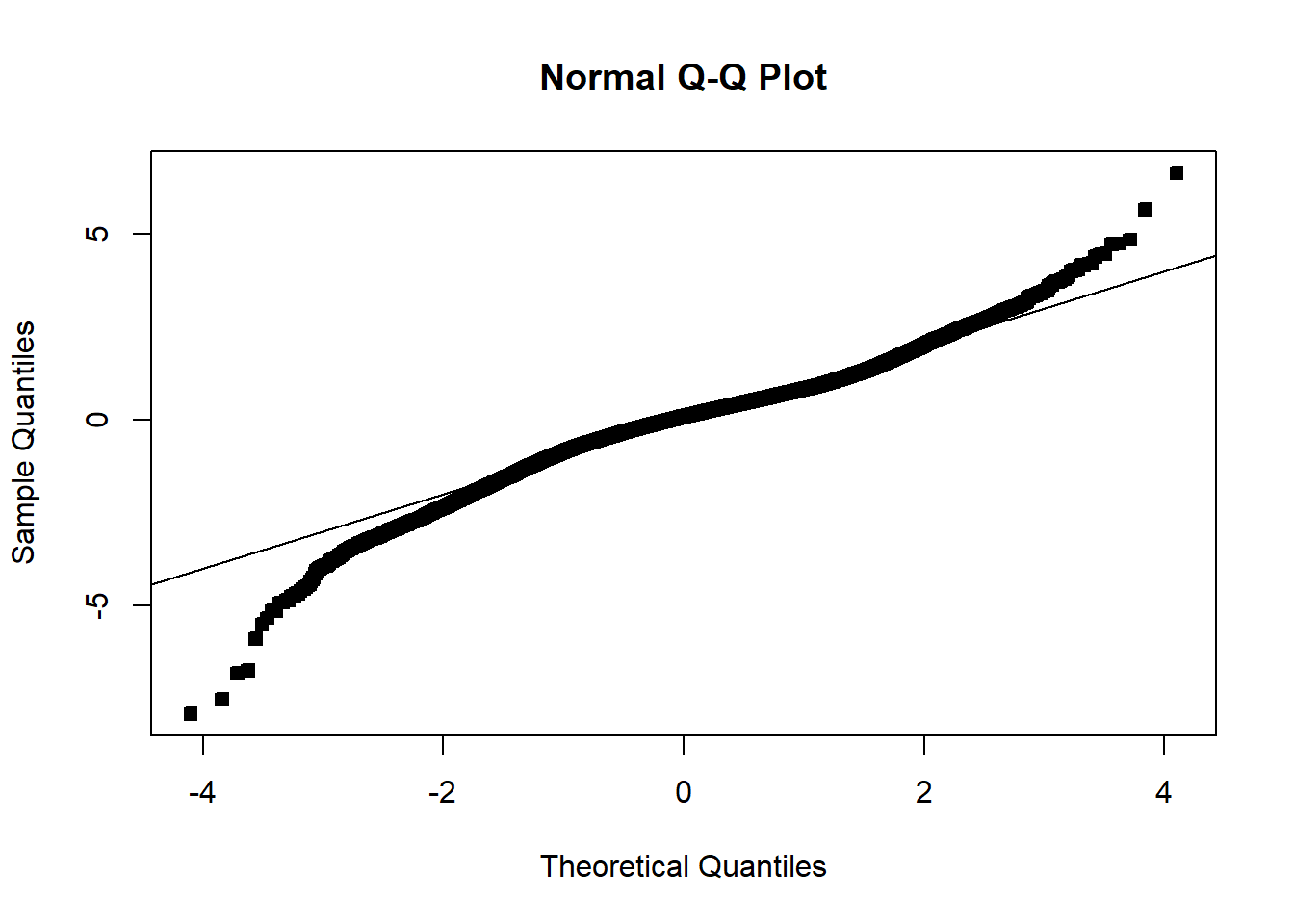
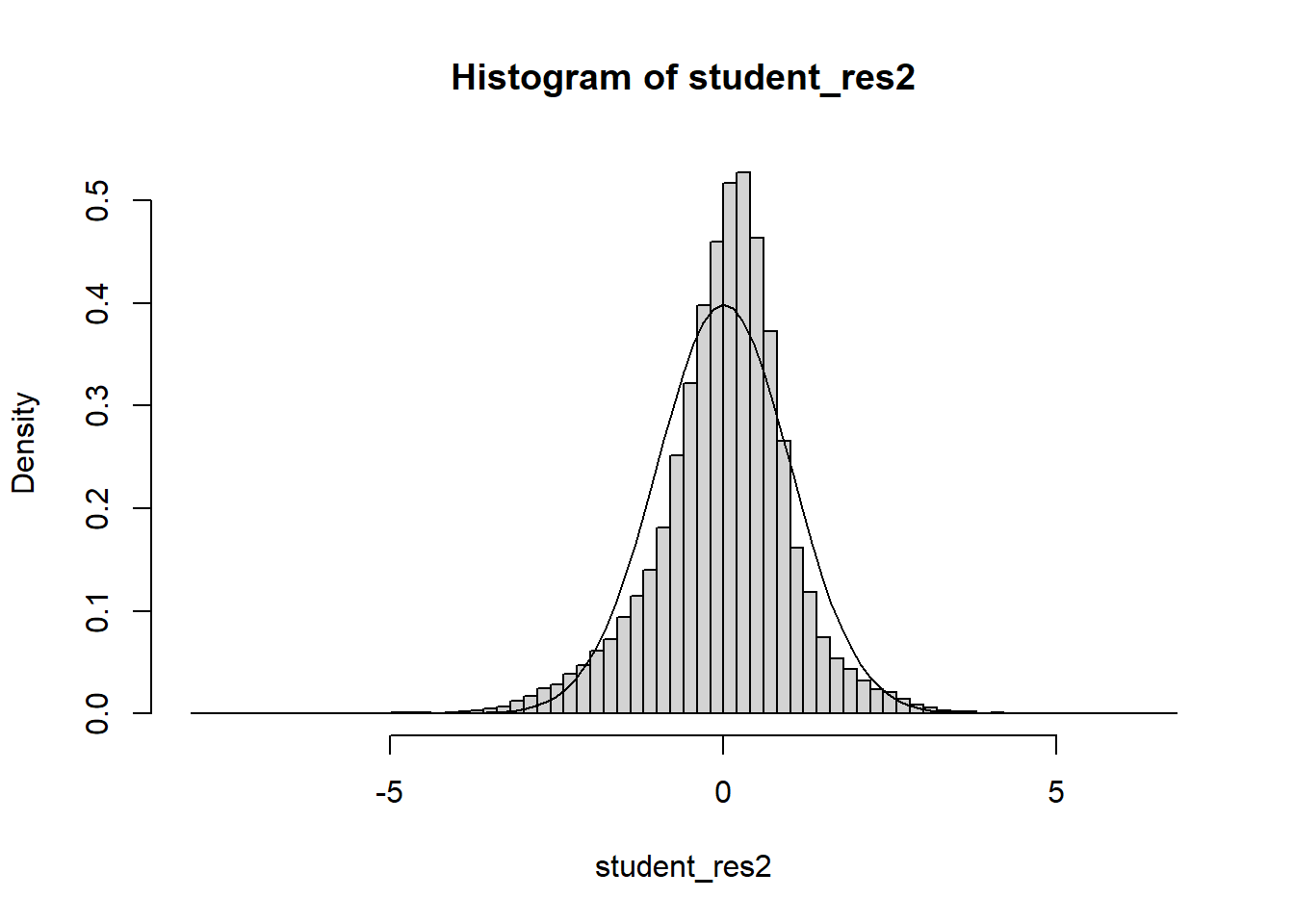
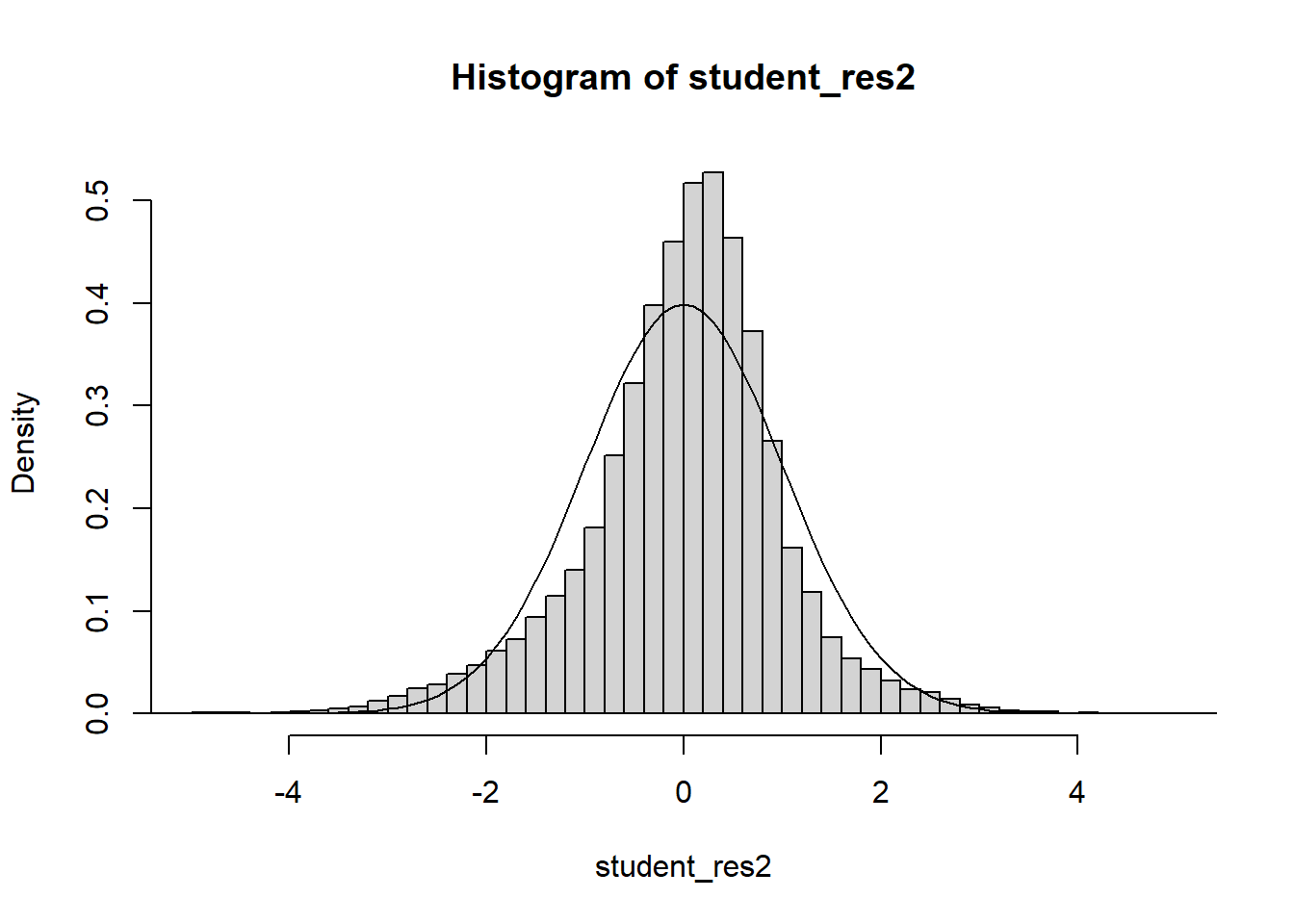
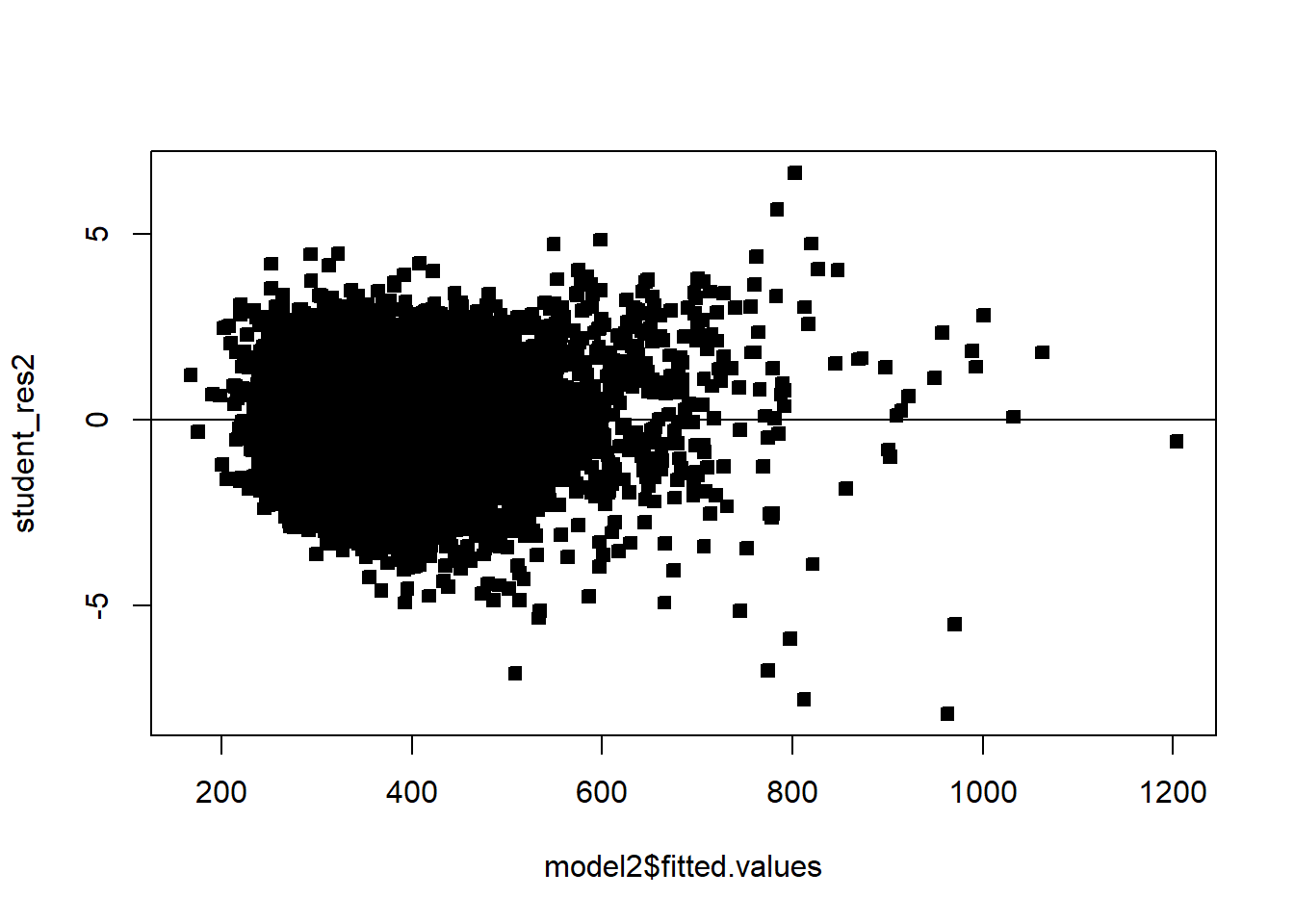
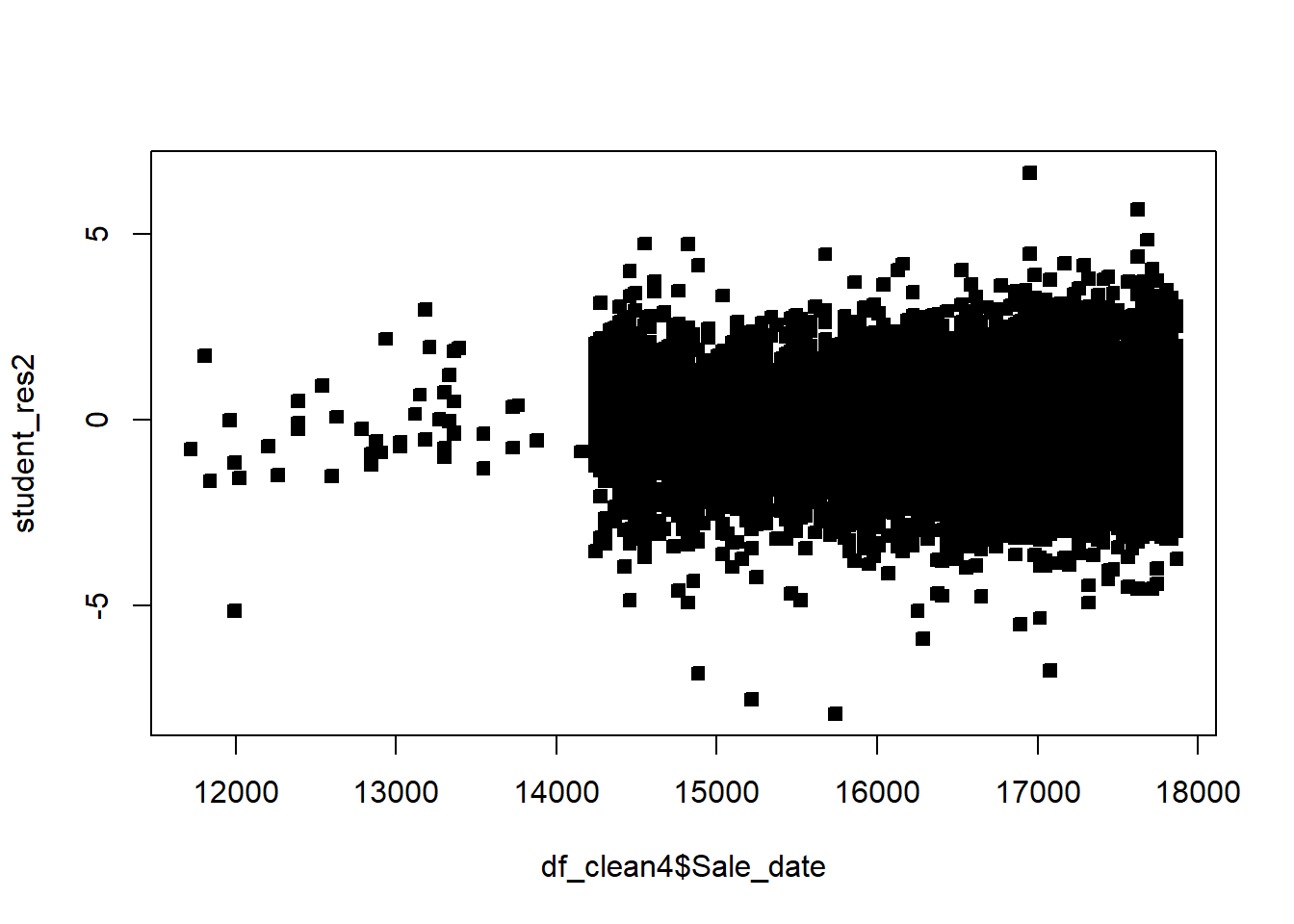
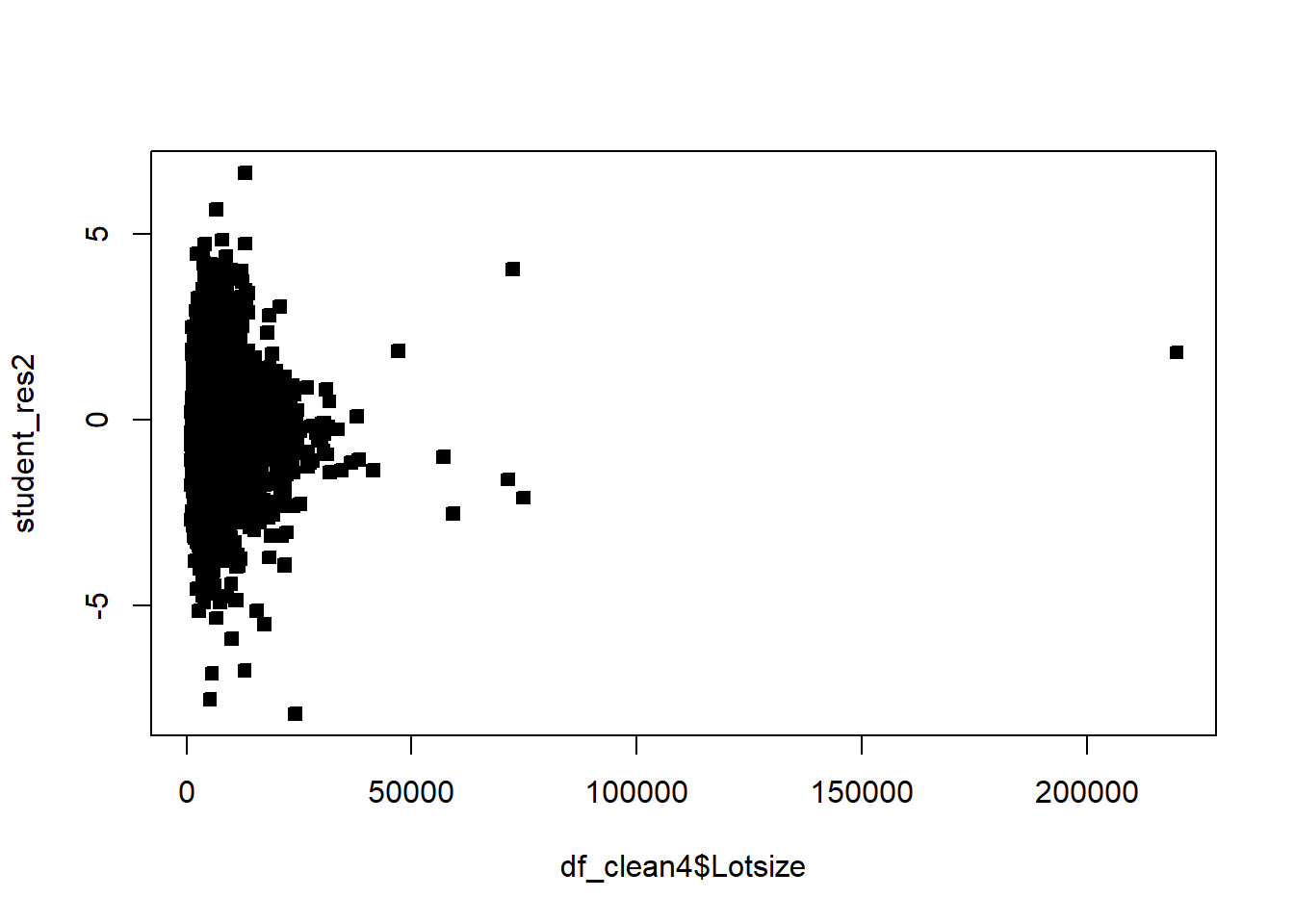
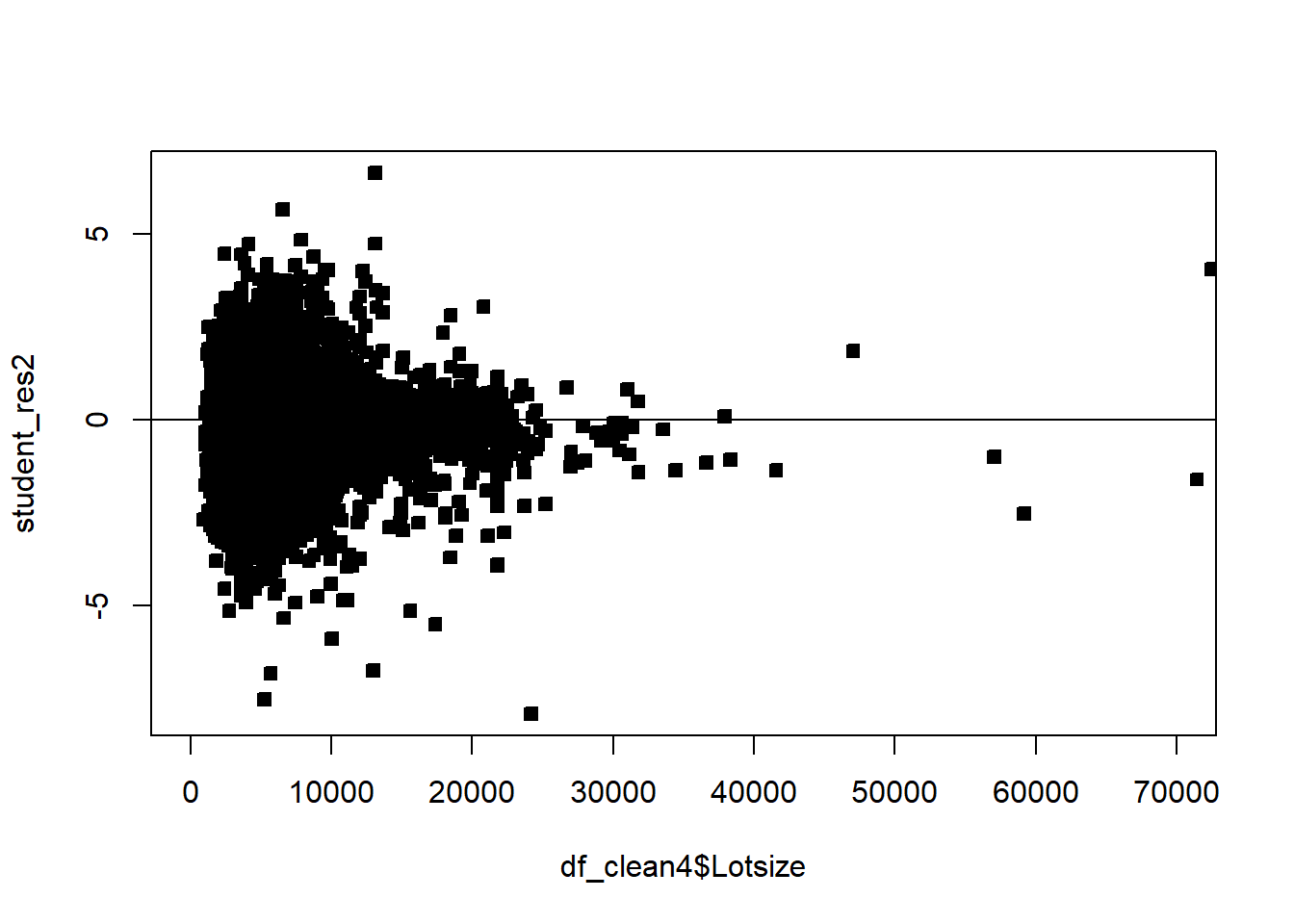
Example 6.6 Explore the pricing data, and evaluate what factors influence the price of a property. Be sure to assess the fit of the model and check assumptions.
####### Packages needed ##############library(lubridate) # Example: We would like to see how sale price # of a home is related to# various factors####### Loading data ##############df_clean2=read.csv('C:/Users/12RAM/OneDrive - York University/Teaching/Courses/Math 3330 Regression/Lecture Codes/clean_data.csv',stringsAsFactors = T)####### Analyzing the data via EDA ##############names(df_clean2)
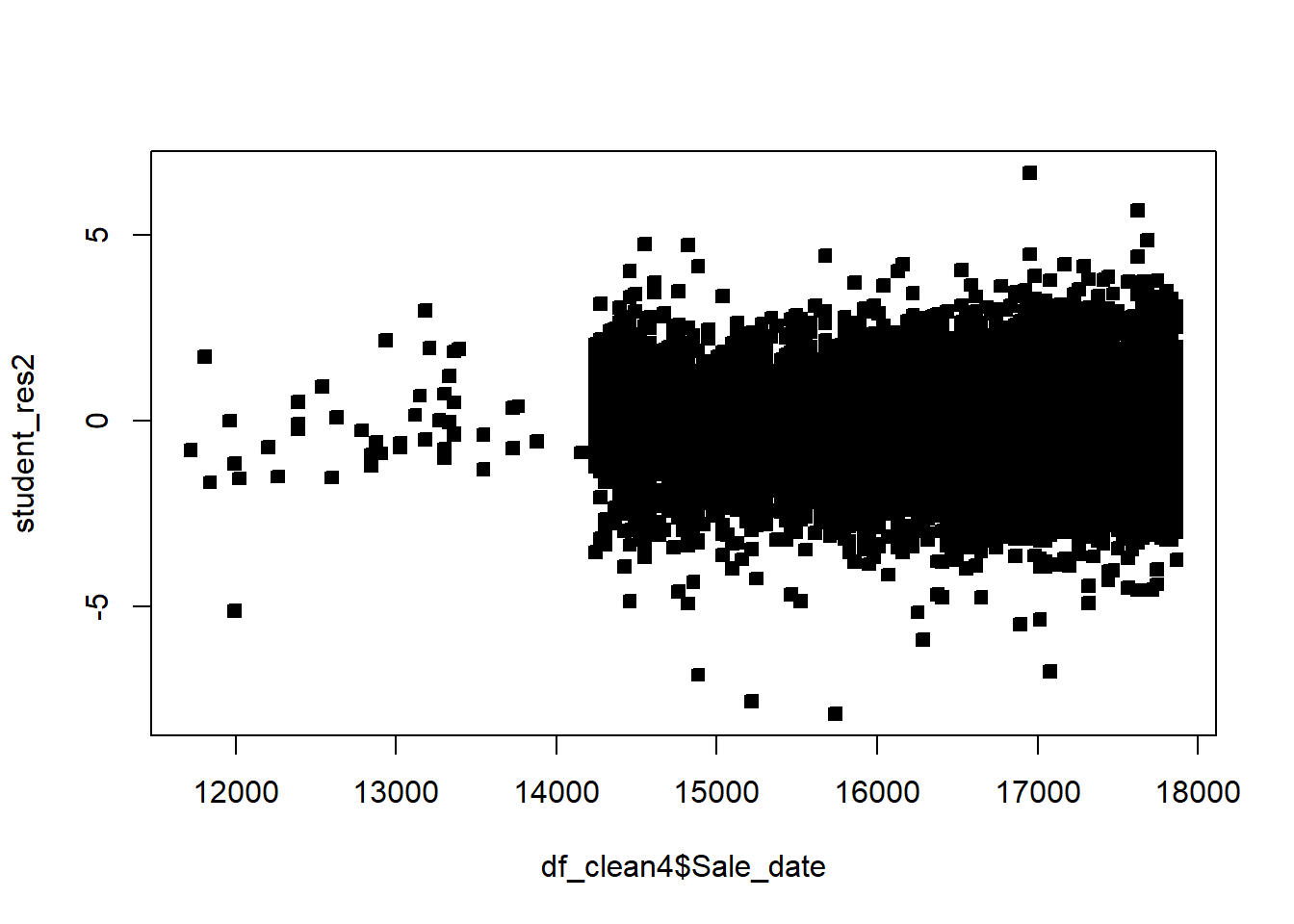
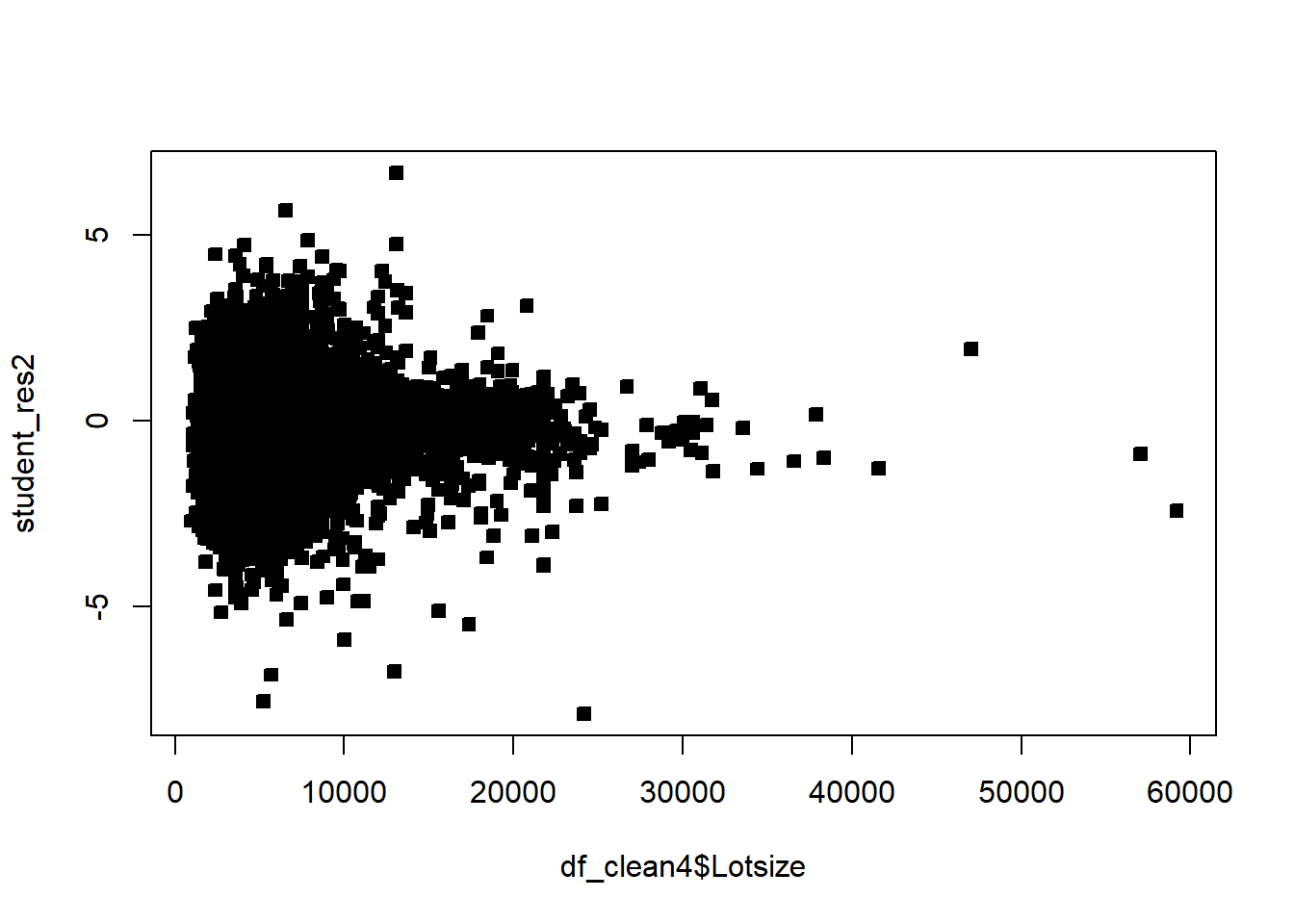
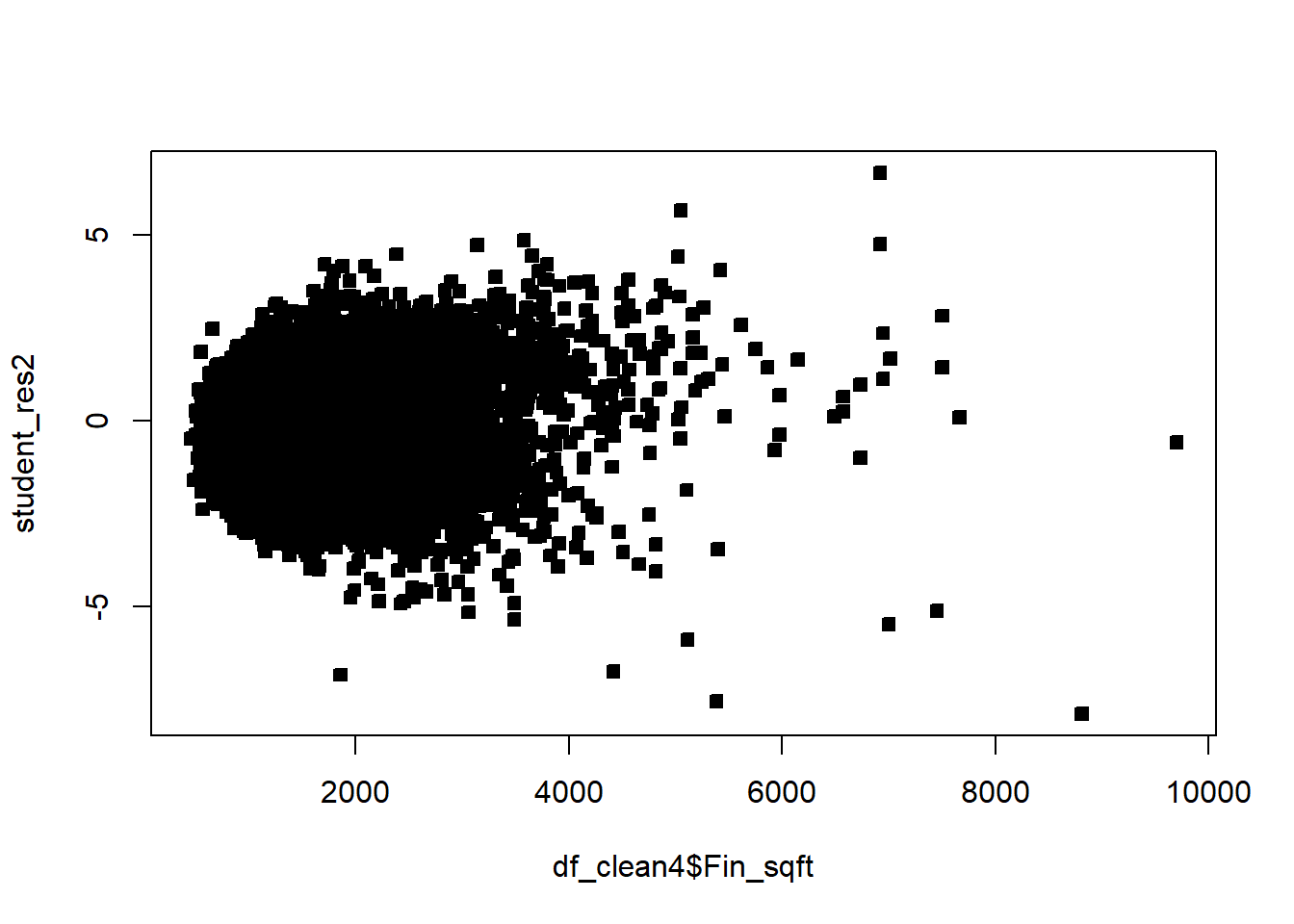
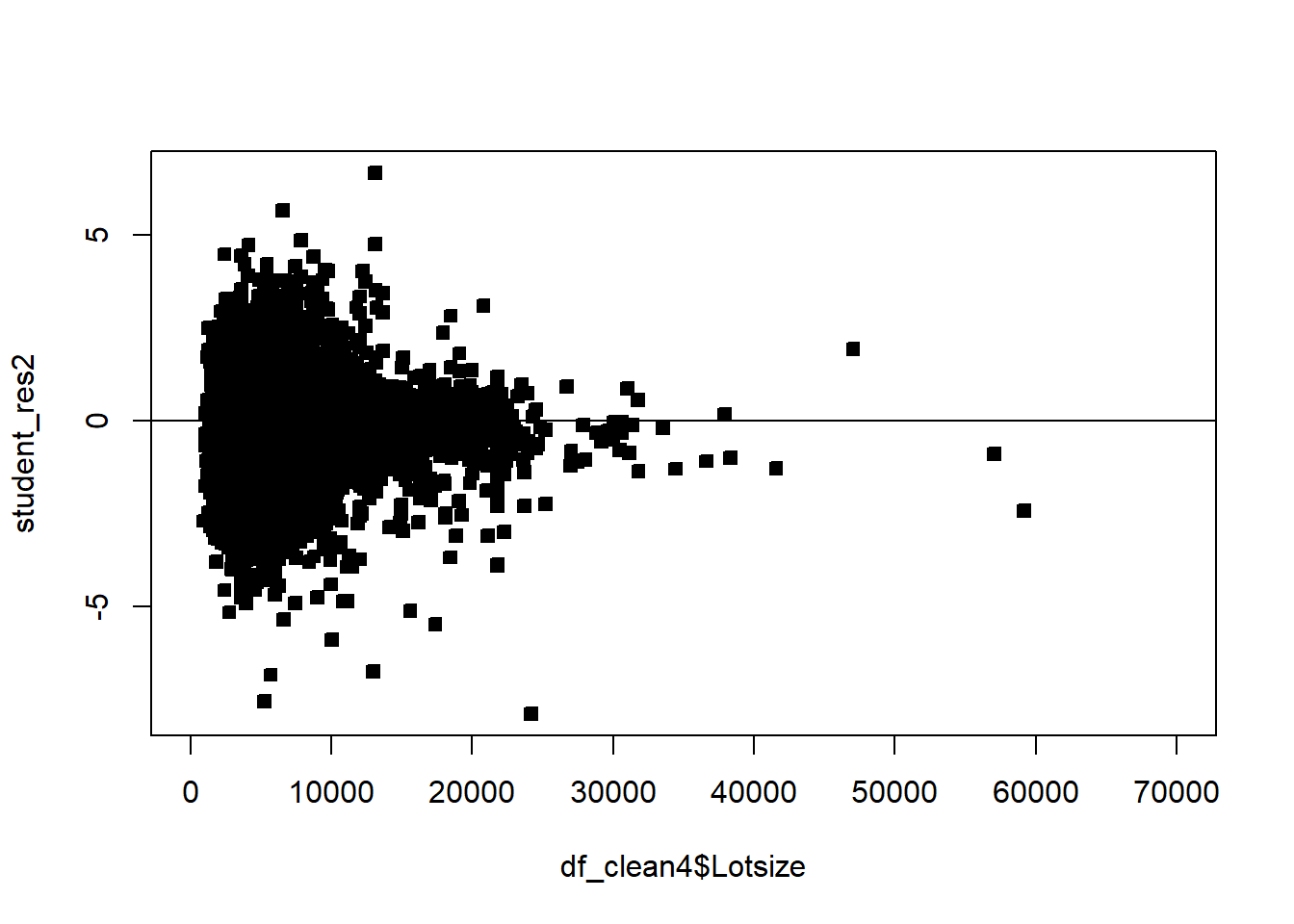
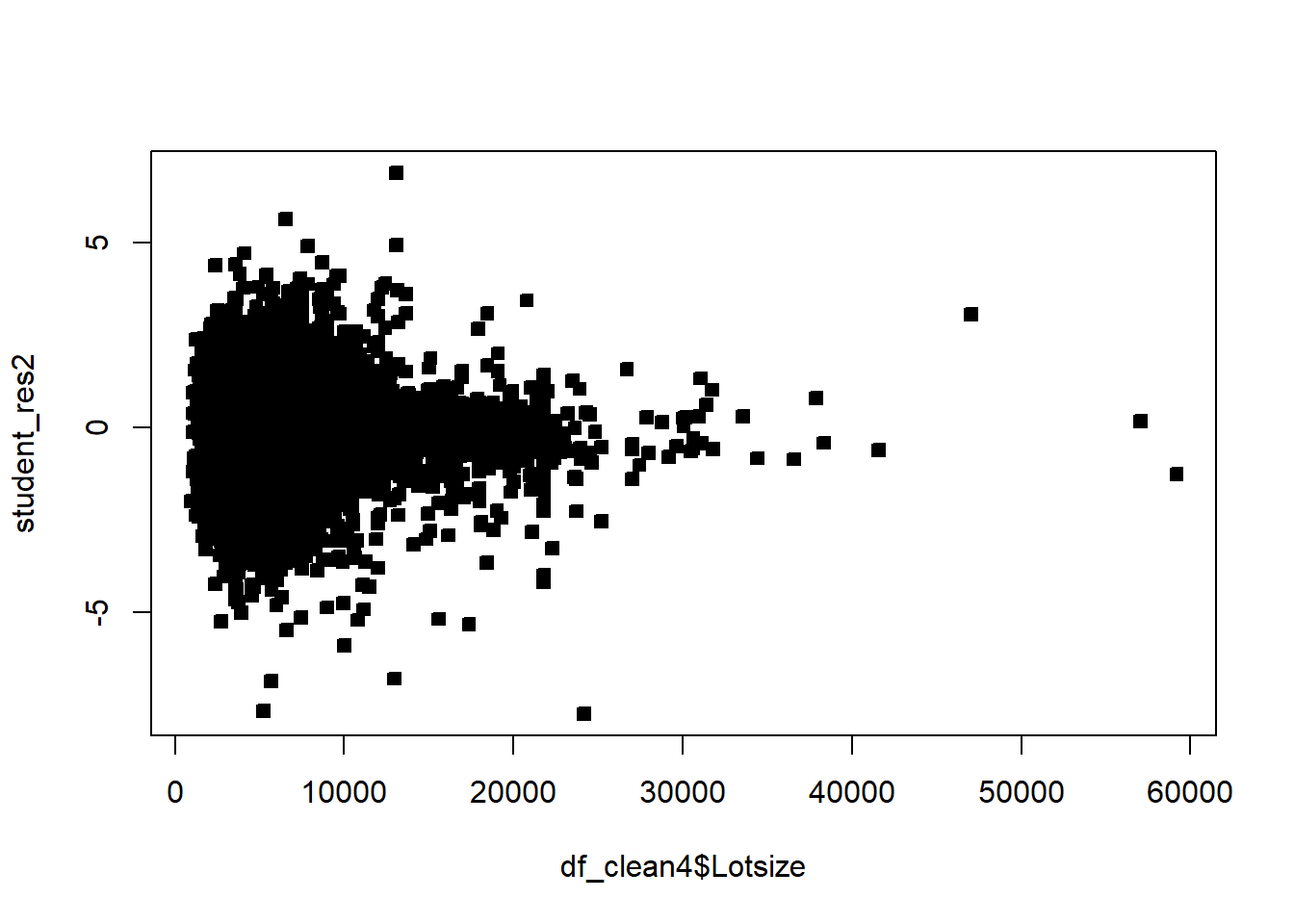
df_clean2$District=as.factor(df_clean2$District)df_clean2=df_clean2[,c('Sale_price','Fin_sqft','District','Sale_date','Year_Built','Lotsize')]# Sale price, as a fn of sq ft, Distict, Sale_date, Year_Built, Lotsizemodel=lm(Sale_price~Fin_sqft+District+Sale_date+ Year_Built+ Lotsize,data=df_clean2)summary(model)
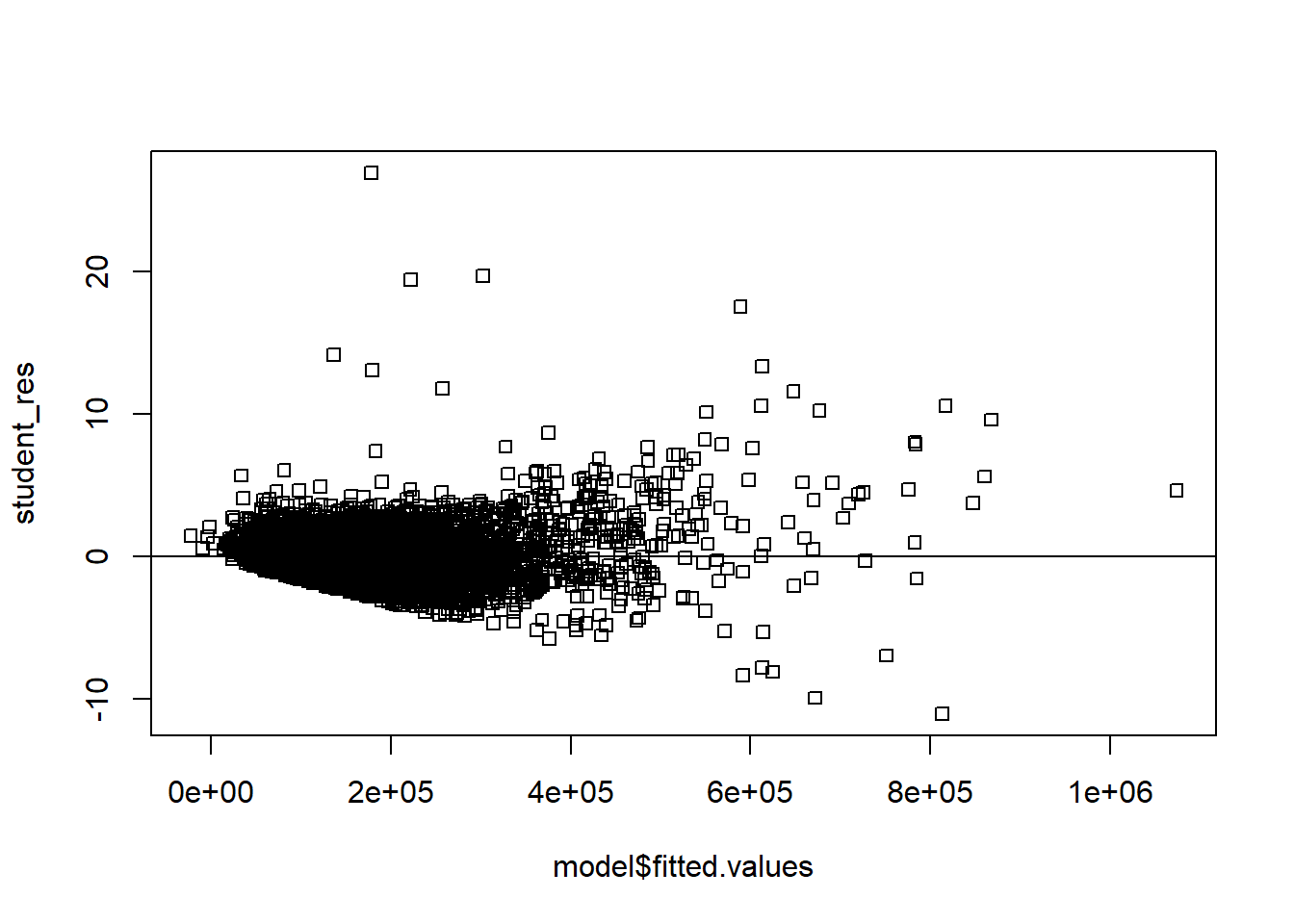
# remove those with 0 lot sizedf3=df_clean2[df_clean2$Lotsize>0,]model=lm(Sale_price~Fin_sqft+District+Sale_date+ Year_Built+ Lotsize,data=df3)summary(model)
# non constant variancerdf=df5rdf=cbind(df5,resid)boxplot(resid~District,rdf )abline(h=0)
6.5 Homework questions
Exercise 6.2 Consider a ML regression model for bread quality against bake time and 3 types of yeast (A, B and C). Write out the dummy variables for the variable yeast type. What is the interpretation of the coefficient of each of the dummy variables, in this context?
Exercise 6.3 Suppose we regress real estate price against number of bathrooms. What is the difference in interpretation between representing number of bedrooms with dummy variables versus a continuous variable?
Exercise 6.4 Consider a ML regression model for bread quality against bake time and 3 types of yeast (A, B and C). Write out the regression equation that includes an interaction between yeast and bake time. What is the interpretation of the coefficient for each of the interaction effects? Compare and contrast the regression model in Exercise 6.2 to this one.